2021年8月1日日曜日
2020年1月26日日曜日
論文読み「Your Classifier Is Secretly An Energy Based Model And You Should Treat It Like One」
はじめに
「Your Classifier Is Secretly An Energy Based Model And You Should Treat It Like One」をまとめる。
概要
Energy Based Model
パラメータ$\theta$を持つ同時確率分布$p_{\theta}({\bf x},y)$をボルツマン分布を用いて表す。 \begin{equation} p_{\theta}({\bf x},y)=\frac{\exp{ \left( -E_{\theta} ({\bf x},y) \right) } }{Z(\theta)} \label{eq1} \end{equation} $E_{\theta}({\bf x},y)$はエネルギーであり、その定義については後述する。$Z(\theta)$は次式で定義される分配関数である。 \begin{equation} Z(\theta)=\int dx\int dy \exp{ \left( -E_{\theta} ({\bf x},y) \right) } \label{eq2} \end{equation} 式(\ref{eq1})のように確率分布をボルツマン分布を用いて表すモデルを、Energy Based Modelと呼ぶ。式(\ref{eq1})を$y$について周辺化して \begin{equation} p_{\theta}({\bf x}) = \int dy\;p_{\theta}({\bf x},y) \label{eq3} \end{equation} を得る。いま、$p_{\theta}({\bf x})$に対してもボルツマン分布を仮定する。 \begin{equation} p_{\theta}({\bf x})=\frac{\exp{\left(-E_{\theta}({\bf x})\right)}}{Z(\theta)} \label{eq5} \end{equation} これを変形すると \begin{eqnarray} \exp{\left(-E_{\theta}({\bf x})\right)} &=& Z(\theta)p_{\theta}({\bf x})\nonumber\\ &=& Z(\theta) \int dy\;p_{\theta}({\bf x},y)\nonumber\\ &=& Z(\theta) \int dy \frac{\exp{ \left( -E_{\theta} ({\bf x},y) \right) }}{Z(\theta)}\nonumber\\ &=& \int dy \exp{ \left( -E_{\theta} ({\bf x},y) \right) } \label{eq6} \end{eqnarray} 両辺の対数を取り \begin{equation} E_{\theta}({\bf x})=-\ln{\left( \int dy \exp{ \left( -E_{\theta} ({\bf x},y) \right) } \right) } \label{eq7} \end{equation} を得る。ここまでの手順をまとめると以下のようになる。
- エネルギー$E_{\theta}({\bf x},y)$を与える。
- 式(\ref{eq1})から$p_{\theta}({\bf x},y)$を計算する。
- 式(\ref{eq7})から$E_{\theta}({\bf x})$を計算する。
- 式(\ref{eq5})から$p_{\theta}({\bf x})$を計算する。
エネルギーの定義
$E_{\theta}({\bf x},y)$について考えるため、従来の識別器の構成を示す(下の左図)。

最適化
学習時に最大化する目的関数は次式である。 \begin{equation} \ln{p_{\theta}({\bf x},y)}=\ln{p_{\theta}({\bf x})}+\ln{p_{\theta}(y|{\bf x})} \label{eq9} \end{equation} 第2項の最大化は従来とおりクロスエントロピーを用いれば良い。第1項の最大化については以下のようにする。最初に、式(\ref{eq5})の両辺の対数をとる。 \begin{equation} \ln{p_{\theta}({\bf x})}=-E_{\theta}({\bf x})-\ln{Z(\theta)} \end{equation} $\theta$で微分すると \begin{equation} \frac{\partial\ln{p_{\theta}({\bf x})}}{\partial\theta}=-\frac{\partial E_{\theta}({\bf x})}{\partial\theta} -\frac{1}{Z(\theta)}\frac{\partial Z(\theta)}{\partial\theta} \end{equation} ここで \begin{equation} Z(\theta)=\int dx \exp{\left(-E_{\theta}({\bf x})\right)} \end{equation} であるから、これを$\theta$で微分すると \begin{equation} \frac{\partial Z(\theta)}{\partial\theta}=\int dx \exp{\left(-E_{\theta}({\bf x})\right)}\left(-\frac{\partial E_{\theta}({\bf x})}{\partial\theta}\right) \end{equation} 故に \begin{eqnarray} \frac{1}{Z(\theta)}\frac{\partial Z(\theta)}{\partial\theta} &=& -\int dx \frac{\exp{\left(-E_{\theta}({\bf x})\right)}}{Z(\theta)} \left(\frac{\partial E_{\theta}({\bf x})}{\partial\theta}\right)\nonumber\\ &=& -\int dx p_{\theta}({\bf x}) \left(\frac{\partial E_{\theta}({\bf x})}{\partial\theta}\right)\nonumber\\ &=&-\mathbb{E}_{ p_{\theta}({\bf x}) } \left[ \frac{\partial E_{\theta}({\bf x})}{\partial\theta} \right] \end{eqnarray} となる。最後の等式は$p_{\theta}({\bf x})$による期待値であることを表す。以上から \begin{equation} \frac{\partial\ln{p_{\theta}({\bf x})}}{\partial\theta}=-\frac{\partial E_{\theta}({\bf x})}{\partial\theta} +\mathbb{E}_{ p_{\theta}({\bf x}) } \left[ \frac{\partial E_{\theta}({\bf x})}{\partial\theta} \right] \end{equation} を得る。$E_{\theta}({\bf x})$は式(\ref{eq7})により計算することができる。上式の第2項は分布$p_{\theta}({\bf x})$からサンプリングする必要がある。 本文献で使用するサンプリング手法は以下の通りである。 \begin{eqnarray} {\bf x}_{0}&\sim&p_0({\bf x}) \nonumber\\ {\bf x}_{i+1}&=&{\bf x}_i-\frac{\alpha}{2}\frac{\partial E_{\theta}({\bf x}_i)}{\partial {\bf x}_i}+\epsilon\nonumber\\ \epsilon&\sim&\mathcal{N}(0,\alpha) \end{eqnarray} ここで、$p_0({\bf x})$は一様分布である。本手法は、Stochastic Gradient Langevin Dynamics(SGLD)をベースにしたものである(詳細は略)。式(\ref{eq9})の第1項は教師なし学習、第2項は教師あり学習を行う。
実験
Hybrid Modelint
従来手法と比較したのが下図である。使用したデータセットは、CIFAR10である。

Calibration
較正済み識別器(calibrated classifier)とは、$\max_y{p(y|{\bf x})}$(確信度)が正解率(accuracy)と比例するような識別器のことである。高い確信度を持って予測されたラベルは高い確率で正解となり、低い確信度で予測されたラベルは、誤認識である確率が高くなる。較正されているか否かを可視化する手順は以下の通り。
- データセット内の各サンプル${\bf x}_i$ごとに$\max_y{p(y|{\bf x}_i)}$を算出し、これらを等区間のバケットに振り分ける(ヒストグラムを作る)。例えば0から1までの区間を20等分した場合、20個のバケットに振り分ける。
- 各バケットに属するサンプルから平均精度を算出し、このバケットの高さとする。
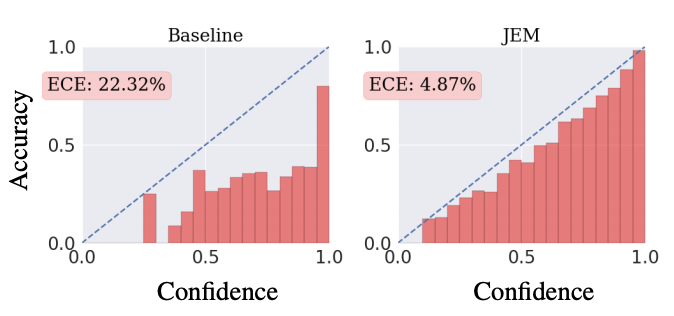
較正度合いを定量化する指標が、次式で定義されるExpected Calibration Error(ECE)である。 \begin{equation} {\rm ECE}=\sum_{m=1}^{M}\frac{|B_m|}{n}|{\rm acc}(B_m)-{\rm conf}(B_m)| \end{equation} ここで、$M$はバケットの数、$n$はデータセット内のサンプル総数、$B_m$は1つののバケット中に格納されるサンプルの集合、$|B_m|$はサンプル数、${\rm acc}(B_m)$は集合$B_m$を用いて計算された平均精度、${\rm conf}(B_m)$は集合$B_m$を用いて計算された平均確信度である。${\rm ECE}$が小さくなるほど較正度合いは良くなり、完全に較正されている場合は0になる。上図に見るように、従来手法による識別器より、JEMで訓練した識別器の方が${\rm ECE}$は小さい。
Out-Of-Distribution Detection
分布外検知とは例えば以下のような識別器を作ることである(引用元)。

データセットCIFAR10で訓練した識別器に別の3つのデータセットSVHN、CIFAR100、CelebAを与えときのサンプルの対数分布($\ln{p(x)}$)を示したのが下図である。
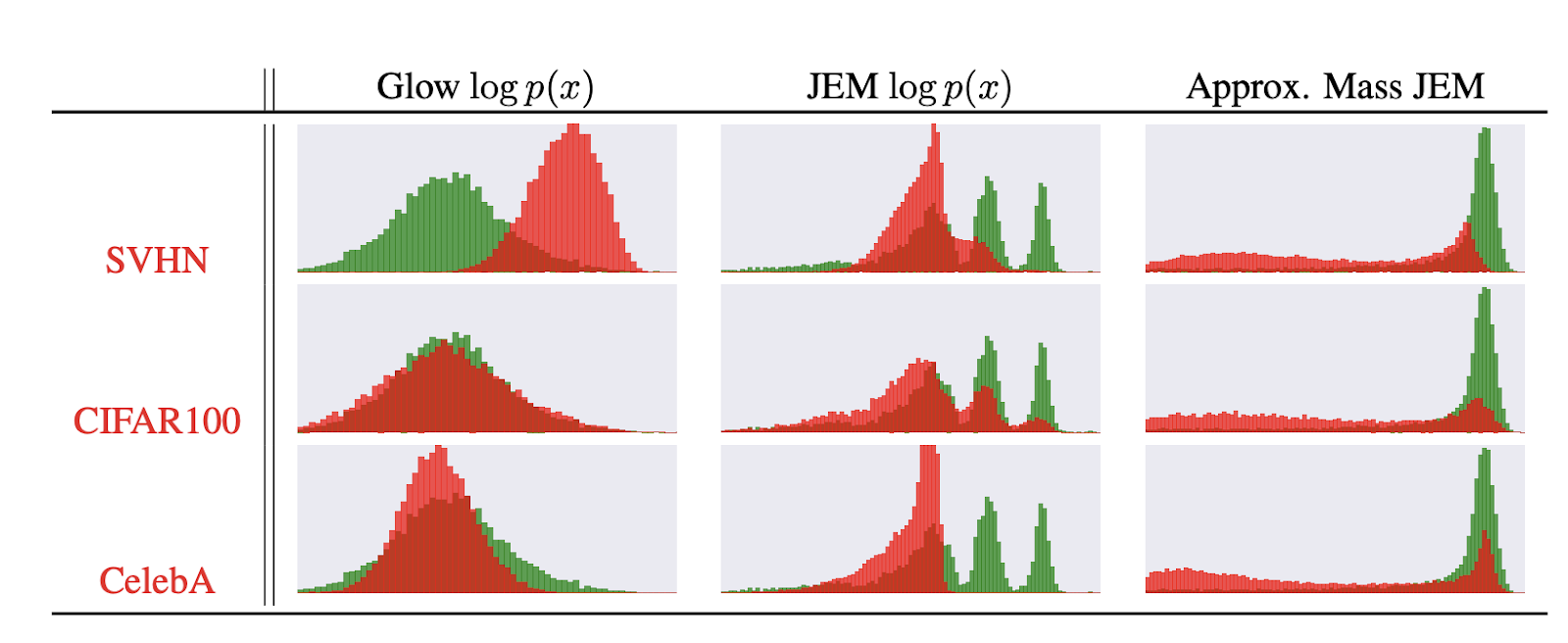
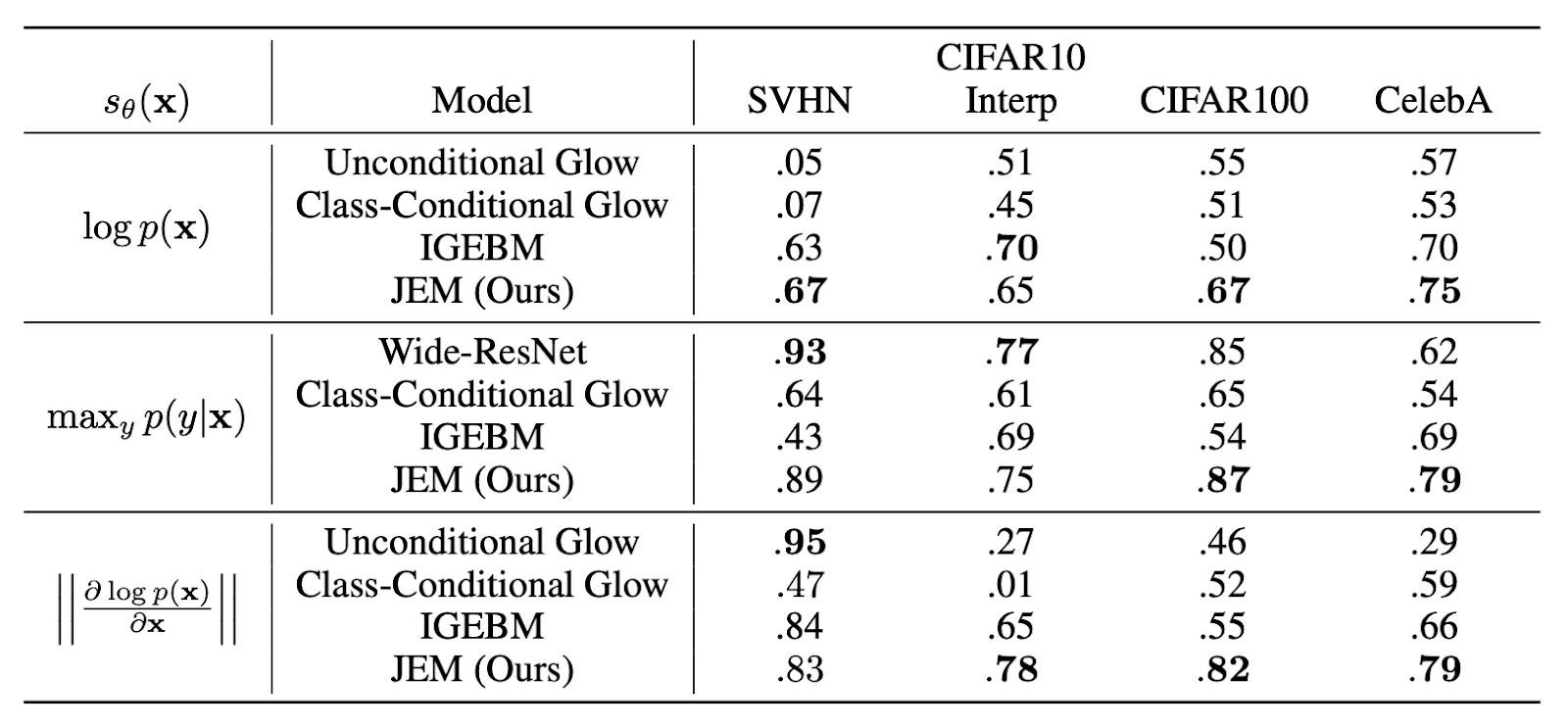
分布外検知に成功している多くの手法が採用している指標が次式である。 \begin{equation} s_{\theta}({\bf x})=\max_y{p_{\theta}(y|{\bf x})} \end{equation}
Robustness
JEMは敵対的サンプルに対しても頑健であると主張されている(詳細は略)。
まとめ
2019年2月24日日曜日
Reinforcement Learning An Introduction 第2版 4章
はじめに
テキストReinforcement Learning An Introduction 第2版の4章で紹介されている以下3つの手法をpythonで実装する。
- Iterative Policy Evaluation
- Policy Iteration
- Value Iteration
コードの場所
今回の全コードはここにある。
Iterative Policy Evaluation
この手法は状態価値関数$V(s)$についての次のベルマン方程式を使う。 \begin{equation} V(s)=\sum_{s^{\prime},a} P(s^{\prime}|s,a)\pi(a|s)\left[r(s,a,s^{\prime})+\gamma V(s^{\prime})\right] \label{eq1} \end{equation} この式の導出はここで行った。テキストに掲載されているIterative Policy Evaluationのアルゴリズムは以下の通りである(テキストPDF版から引用した)。

#!/usr/bin/env python
# -*- coding: utf-8 -*-
from common import * # noqa
def update(v, state, gamma, reward):
updated_v = 0.0
for action in ACTIONS.values():
next_state = state + action
if not is_on_grid(next_state):
next_state = state
updated_v += 0.25 * (reward + gamma * v[next_state])
return updated_v
def main():
v = initialize_value_function(ROWS, COLS)
k = 0
while True:
delta = 0
for state in state_generator(ROWS, COLS):
if is_terminal_state(state):
continue
tmp = v[state]
v[state] = update(v, state, GAMMA, REWARD)
delta = max(delta, abs(tmp - v[state]))
k += 1
if delta < THRESHOLD:
break
print("iteration size: {}".format(k))
display_value_function(v)
if __name__ == "__main__":
main()
実行結果は以下である。
iteration size: 88 value funtion: [[ 0. -13.99330608 -19.99037659 -21.98940765] [-13.99330608 -17.99178568 -19.99108113 -19.99118312] [-19.99037659 -19.99108113 -17.99247411 -13.99438108] [-21.98940765 -19.99118312 -13.99438108 0. ]]小数点以下を四捨五入すれば、テキストの$k=\infty$の場合の数値と一致する。
Policy Iteration
この手法は、Policy Evaluationに対しては式(\ref{eq1})を、Policy Improvementに対しては次のベルマン最適方程式を使う。 \begin{equation} V^{*}(s)=\max_{a}\sum_{s^{\prime}} P(s^{\prime}|s,a)\left[r(s,a,s^{\prime})+\gamma V^{*}(s^{\prime})\right] \label{eq2} \end{equation} ただし、これをそのまま使うのではなく、次のようにしてpolicy更新のために利用する。 \begin{equation} \pi(a|s)={\rm arg}\max_{a}\sum_{s^{\prime}} P(s^{\prime}|s,a)\left[r(s,a,s^{\prime})+\gamma V(s^{\prime})\right] \label{eq3} \end{equation} 右辺を最大にするものが$N$個ある場合、各行動の実現確率を$1/N$とする。最大にしない行動には確率0を割り振る。 テキストにあるアルゴリズムは以下の通りである(PDF版から引用した)。

#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
from common import * # noqa
def evaluate_policy(rows, cols, v, policy, gamma, reward, threshold):
while True:
delta = 0
for state in state_generator(rows, cols):
if is_terminal_state(state):
continue
tmp = v[state]
v[state] = update_value_function(v, policy, state, gamma, reward)
delta = max(delta, abs(tmp - v[state]))
if delta < threshold:
break
def update_value_function(v, policy, state, gamma, reward):
action_prob = policy[state]
updated_v = 0
for action_key, prob in zip(ACTIONS.keys(), action_prob):
next_state = state + ACTIONS[action_key]
if not is_on_grid(next_state):
next_state = state
updated_v += prob * (reward + gamma * v[next_state])
return updated_v
def update_policy(state, reward, gamma, v):
results = {}
for key in ACTIONS:
next_state = ACTIONS[key] + state
if not is_on_grid(next_state):
next_state = state
results[key] = reward + gamma * v[next_state]
max_vs = max(results.values())
return [k for k, val in results.items() if val == max_vs]
def improve_policy(rows, cols, policy, reward, gamma, v):
is_stable = True
for state in state_generator(rows, cols):
if is_terminal_state(state):
continue
old_action_prob = policy[state].copy()
new_policy = update_policy(state, reward, gamma, v)
overwrite_policy(state, new_policy, policy)
if not np.all(old_action_prob == policy[state]):
is_stable = False
return is_stable
def main():
v = initialize_value_function(ROWS, COLS)
policy = initialize_policy(ROWS, COLS)
while True:
evaluate_policy(ROWS, COLS, v, policy, GAMMA, REWARD, THRESHOLD)
is_stable = improve_policy(ROWS, COLS, policy, REWARD, GAMMA, v)
if is_stable:
break
display_policy(policy)
display_value_function(v)
if __name__ == "__main__":
main()
実行結果は以下の通り。
policy --- 0 1 left 0 2 left 0 3 down:left 1 0 up 1 1 up:left 1 2 up:right:down:left 1 3 down 2 0 up 2 1 up:right:down:left 2 2 right:down 2 3 down 3 0 up:right 3 1 right 3 2 right value function --- [[ 0. -1. -2. -3.] [-1. -2. -3. -2.] [-2. -3. -2. -1.] [-3. -2. -1. 0.]]policyの出力は、(行番号、列番号、矢印の向き)の順に並んでいる。
Value Iteration
本手法は式(\ref{eq2})を用いて状態価値関数$V(s)$を更新する。policy$(\pi(a|s))$の決定には式(\ref{eq3})を使う。 テキストにあるアルゴリズムは以下の通りである(PDF版から引用した)。

#!/usr/bin/env python
# -*- coding: utf-8 -*-
from common import * # noqa
import policy_iteration
def update(v, state, gamma, reward):
results = {}
for key in ACTIONS:
next_state = state + ACTIONS[key]
if not is_on_grid(next_state):
next_state = state
results[key] = reward + gamma * v[next_state]
max_vs = max(results.values())
return max_vs
def make_policy(v, rows, cols, reward, gamma):
policy = initialize_policy(rows, cols)
for state in state_generator(rows, cols):
if is_terminal_state(state):
continue
op = policy_iteration.update_policy(state, reward, gamma, v)
overwrite_policy(state, op, policy)
return policy
def main():
v = initialize_value_function(ROWS, COLS)
while True:
delta = 0
for state in state_generator(ROWS, COLS):
if is_terminal_state(state):
continue
tmp = v[state]
v[state] = update(v, state, GAMMA, REWARD)
delta = max(delta, abs(tmp - v[state]))
if delta < THRESHOLD:
break
policy = make_policy(v, ROWS, COLS, REWARD, GAMMA)
display_policy(policy)
display_value_function(v)
if __name__ == "__main__":
main()
実行結果の以下の通り。
policy --- 0 1 left 0 2 left 0 3 down:left 1 0 up 1 1 up:left 1 2 up:right:down:left 1 3 down 2 0 up 2 1 up:right:down:left 2 2 right:down 2 3 down 3 0 up:right 3 1 right 3 2 right value function --- [[ 0. -1. -2. -3.] [-1. -2. -3. -2.] [-2. -3. -2. -1.] [-3. -2. -1. 0.]]Policy Iterationのときと同じ結果である。
まとめ
「Policy Iteration」と「Value Iteration」の結果は同じになるが、テキストp.77に掲載されている矢印の向きと少し違う。異なる箇所は、2行3列目と3行2列目のマスである。 間違いが分かる方、ご指摘ください。
2018年11月30日金曜日
Conditional Random Field
はじめに
この文献をベースにしてCRFについてまとめる。
CRFモデル
いま、入力系列を$x_{1:N}(=x_1,\cdots,x_N)$、出力系列を$z_{1:N}(=z_1,\cdots,z_N)$と置き、下のグラフィカルモデルを考える。

素性関数(Feature Function)
指数関数の肩の部分を展開すると \begin{eqnarray} \sum_{n=1}^N\sum_{i=1}^F\lambda_i f_i\left(z_{n-1},z_n,x_{1:N},n\right) &=& \lambda_1\sum_{n=1}^N f_1\left(z_{n-1},z_n,x_{1:N},n\right)\\ &+& \lambda_2\sum_{n=1}^N f_2\left(z_{n-1},z_n,x_{1:N},n\right)\\ &+& \lambda_3\sum_{n=1}^N f_3\left(z_{n-1},z_n,x_{1:N},n\right)\\ &+& \cdots\nonumber\\ &+& \lambda_F\sum_{n=1}^N f_F\left(z_{n-1},z_n,x_{1:N},n\right)\nonumber\\ \end{eqnarray} となる。先に関数$f_i(\cdot)$はあらかじめ決めて置く量であると書いた。例えば以下のように与えることができる。 \begin{eqnarray} f_1\left(z_{n-1},z_n,x_{1:N},n\right)&=& \begin{cases} 1&\mbox{if $z_n$=PERSON and $x_n$=John}\\ 0&\mbox{otherwise} \end{cases}\\ f_2\left(z_{n-1},z_n,x_{1:N},n\right)&=& \begin{cases} 1&\mbox{if $z_n$=PERSON and $x_{n+1}$=said}\\ 0&\mbox{otherwise} \end{cases}\\ f_3\left(z_{n-1},z_n,x_{1:N},n\right)&=& \begin{cases} 1&\mbox{if $z_{n-1}$=OTHER and $z_{n}$=PERSON}\\ 0&\mbox{otherwise} \end{cases} \end{eqnarray} $f_1(\cdot)$は、同じ場所の入力値$x_n$と出力値$z_n$から決まる素性である。一方、$f_2(\cdot)$は、現在の出力値$z_n$と次の入力値$x_{n+1}$から決まる素性となっている。また、$f_3(\cdot)$は2つの隣接する出力値$z_{n-1},z_n$から決まる素性である。もちろん、$f_i(\cdot)$は2値である必要はなく、実数値を取る関数を与えることもできる。 いま \begin{eqnarray} F_1&=&\sum_{n=1}^N f_1\left(z_{n-1},z_n,x_{1:N},n\right) \\ F_2&=&\sum_{n=1}^N f_2\left(z_{n-1},z_n,x_{1:N},n\right) \\ F_3&=&\sum_{n=1}^N f_3\left(z_{n-1},z_n,x_{1:N},n\right) \end{eqnarray} などと置くと、指数型の部分は \begin{equation} \sum_{n=1}^N\sum_{i=1}^F\lambda_i f_i\left(z_{n-1},z_n,x_{1:N},n\right)=(\lambda_1,\cdots,\lambda_N) \cdot (F_1,\cdots,F_N)^T \end{equation} と書くことができる。$F=(F_1,\cdots,F_N)$を素性ベクトルと呼ぶ。
CRFの最適化
先に書いたようにCRFのパラメータ$\lambda_i$は学習により決まる量である。最尤推定法を用いる。 \begin{equation} L=\left(\prod_{j=1}^M p(z_{1:N}^{(j)}|x_{1:N}^{(j)})\right)p(\lambda_{1:F}) \end{equation} ただし、$\lambda_i$についての事前確率 \begin{eqnarray} p(\lambda_{1:F})&=&\prod_{i=1}^F p(\lambda_{i})\\ p(\lambda_{i})&=&\mathcal{N}(\lambda_i|0,\sigma^2) \end{eqnarray} を導入した。両辺対数を取れば \begin{equation} \ln{L}=\sum_{j=1}^M \ln{p(z_{1:N}^{(j)}|x_{1:N}^{(j)})}-\frac{1}{2}\sum_i^F\frac{\lambda_i^2}{\sigma^2} \end{equation} $\lambda_k$で微分する。 \begin{equation} \frac{\partial L}{\partial\lambda_k} = \sum_j\sum_n f_k(z_{n-1}^{(j)},z_n^{(j)},x_{1:N}^{(j)},n)- \frac{\partial}{\partial\lambda_k}\sum_j\ln{Z^{(j)}}- \frac{\lambda_k}{\sigma^2} \end{equation} ここで \begin{eqnarray} \frac{\partial\ln{Z^{(j)}}}{\partial\lambda_k} &=& \frac{1}{Z^{(j)}}\frac{\partial Z^{(j)}}{\partial\lambda_k}\\ &=& \sum_n\sum_{z_{n-1},z_n}p(z_{n-1},z_{n}|x_{1:N})f_k(z_{n-1}^{(j)},z_n^{(j)},x_{1:N}^{(j)},n)\\ &=& \sum_n\mathbb{E}_{z_{n-1},z_n} \left[ f_k(z_{n-1}^{(j)},z_n^{(j)},x_{1:N}^{(j)},n) \right] \end{eqnarray} 従って \begin{equation} \frac{\partial L}{\partial\lambda_k} = \sum_j\sum_n f_k(z_{n-1}^{(j)},z_n^{(j)},x_{1:N}^{(j)},n)- \sum_j\sum_n\mathbb{E}_{z_{n-1},z_n} \left[ f_k(z_{n-1}^{(j)},z_n^{(j)},x_{1:N}^{(j)},n) \right] - \frac{\lambda_k}{\sigma^2} \end{equation} を得る。解析的には解けないので、例えば、勾配降下法を用いて近似解を計算することになる。 \begin{equation} \lambda_k\leftarrow\lambda_k-\eta \frac{\partial L}{\partial\lambda_k} \end{equation}
2018年11月18日日曜日
ディープニューラルネットワークとガウス過程の関係
はじめに
ディープニューラルネットワークとガウス過程の関係をまとめる。先のページの続きである。
ディープニューラルネットワーク
以下のネットワークを考える。

ガウス過程との関係
$z^l_i$がガウス過程と等価となることを帰納法により証明する。
$l=0,1$のとき、先のページでの議論から$z^0_i$と$z^1_i$はガウス過程に従う量である。 いま、$z^{l-1}_i$がガウス過程に従う量であるとする。このとき、式(\ref{eq1})から$x_j^l$と$x_{j^{\prime}}^l$は、$j\neq j^{\prime}$のとき、独立である。式(\ref{eq2})から$z_i^l$は独立同分布から生成される項の和となるから、$N_l\rightarrow\infty$の極限で、$z_i^l$はガウス分布に従う(中心極限定理)。以上により、$z^l_i$がガウス過程と等価となることが証明された。ただし、$N_{0}\rightarrow\infty,N_{1}\rightarrow\infty,\cdots,N_{l-1}\rightarrow\infty,N_{l}\rightarrow\infty$の順に極限を取る必要がある。
平均と共分散行列の導出
$z^l_i$がガウス過程であることが示されたので、その平均と共分散行列を導く。平均は以下となる。 \begin{eqnarray} \mathbb{E}\left[z^l_i(x)\right] &=& \mathbb{E}\left[b_i^l\right]+\sum_{j=1}^{N_l}\mathbb{E}\left[W_{ij}^l x_j^l(x)\right]\\ &=& \mathbb{E}\left[b_i^l\right]+\sum_{j=1}^{N_l}\mathbb{E}_l\left[W_{ij}^l\right]\mathbb{E}_{l-1}\left[ x_j^l(x)\right] \end{eqnarray} ここで、$\mathbb{E}\left[b_i^l\right]=0,\mathbb{E}_l\left[W_{ij}^l\right]=0$であるから、$\mathbb{E}\left[z^l_i\right]=0$を得る。共分散行列は次式となる。 \begin{eqnarray} \mathbb{E}\left[z^l_i(x)z^l_i(x^{\prime})\right] &=& \mathbb{E}_l\left[b_i^l b_i^l\right]+ \sum_{j=1}^{N_l}\sum_{k=1}^{N_l} \mathbb{E}_l\left[W_{ij}^l W_{ik}^l\right] \mathbb{E}_{l-1}\left[x_j^l(x) x_k^l(x^{\prime})\right] \end{eqnarray} ここで \begin{eqnarray} \mathbb{E}_l\left[b_i^l b_i^l\right]&=&\sigma_b^2 \\ \mathbb{E}_l\left[W_{ij}^l W_{ik}^l\right]&=&\frac{\sigma_w^2}{N_l}\delta_{jk} \end{eqnarray} であるから \begin{eqnarray} \mathbb{E}\left[z^l_i(x)z^l_i(x^{\prime})\right] &=& \sigma_b^2+ \frac{\sigma_w^2}{N_l} \sum_{j=1}^{N_l} \mathbb{E}_{l-1}\left[x_j^l(x) x_j^l(x^{\prime})\right]\\ &=& \sigma_b^2+ \frac{\sigma_w^2}{N_l} \mathbb{E}_{l-1}\left[\sum_{j=1}^{N_l} x_j^l(x) x_j^l(x^{\prime})\right]\\ &=& \sigma_b^2+ \frac{\sigma_w^2}{N_l} \mathbb{E}_{l-1}\left[x^l(x)^T x^l(x^{\prime})\right]\\ &=& \sigma_b^2+ \frac{\sigma_w^2}{N_l} \mathbb{E}_{l-1}\left[ \phi\left(z^{l-1}\left(x\right)\right)^T \phi\left(z^{l-1}\left(x^{\prime}\right)\right) \right]\label{eq3}\\ &\equiv&K^l(x,x^{\prime}) \end{eqnarray} となる。$N$個の入力ベクトル$\left(x^{(1)},\cdots,x^{(N)}\right)$に対応する次の量 \begin{equation} {\bf z}_i^l=\left(z_i^l\left(x^{(1)}\right),\cdots,z_i^l\left(x^{(N)}\right)\right) \end{equation} は、ガウス分布$\mathcal{N}({\bf 0},K^l)$に従う。ここで、$K^l$の$(n,m)$成分は次式で与えられる。 \begin{equation} K_{nm}^l=K^l\left(x^{(n)},x^{(m)}\right) \end{equation} 式(\ref{eq3})の第2項にある期待値の計算を進める。表記を簡単にするため、$x^{(n)}$を$x_n$などと置くことにする。 \begin{eqnarray} A&\equiv& \mathbb{E}_{l-1}\left[ \phi\left(z^{l-1}\left(x_n\right)\right)^T \phi\left(z^{l-1}\left(x_m\right)\right) \right]\\ &=& \sum_{j=1}^{N_l}\mathbb{E}_{l-1}\left[ \phi\left(z^{l-1}_j\left(x_n\right)\right) \phi\left(z^{l-1}_j\left(x_m\right)\right) \right]\\ &=& \sum_{j=1}^{N_l} \int dz_j^{l-1}(x_1)\cdots dz_j^{l-1}(x_N) \phi\left(z^{l-1}_j\left(x_n\right)\right) \phi\left(z^{l-1}_j\left(x_m\right)\right)\\ &\times& \mathcal{N}(z_j^{l-1}(x_1)\cdots z_j^{l-1}(x_N)|{\bf 0},K^{l-1}) \end{eqnarray} 上の積分は、$z_j^{l-1}(x_n)$と$z_j^{l-1}(x_m)$以外の変数については実行できる。 \begin{eqnarray} A &=& \sum_{j=1}^{N_l} \int dz_j^{l-1}(x_n) dz_j^{l-1}(x_m) \phi\left(z^{l-1}_j\left(x_n\right)\right) \phi\left(z^{l-1}_j\left(x_m\right)\right)\\ &\times& \mathcal{N}(z_j^{l-1}(x_n),z_j^{l-1}(x_m)|{\bf 0},\Psi^{l-1}) \end{eqnarray} ここで \begin{equation} \Psi^{l-1}=\left( \begin{array}{cc} K^{l-1}_{nn} & K^{l-1}_{nm} \\ K^{l-1}_{mn} & K^{l-1}_{mm} \end{array} \right) \end{equation} とした。すなわち、$A$は3つの量、$K^{l-1}_{nn},K^{l-1}_{nm}(=K^{l-1}_{mn}),K^{l-1}_{mm}$と活性化関数$\phi$に依存する量であることがわかる。以上から \begin{equation} K^l_{nm}=\sigma_b^2+\sigma_w^2F_{\phi}(K^{l-1}_{nn},K^{l-1}_{nm},K^{l-1}_{mm}) \end{equation} と書くことができる。$F$は$\phi$の形が決まれば計算できる関数である。上の式から、$K^l$は$K^{l-1}$を用いて計算できることが分かる。
参考文献
Deep Neural Networks as Gaussian Processes
2018年11月10日土曜日
1層のニューラルネットワークとガウス過程の関係
はじめに
1層のニューラルネットワークとガウス過程の関係をまとめる。
1層のニューラルネットワーク
下図のニューラルネットワークを考える。

ガウス過程との関係
パラメータ$W^0_{jk}$と$b^0_j$はそれぞれ独立同分布から生成されると仮定したので、$x_j^1$と$x_{j^{\prime}}^1$は、$j\neq j^{\prime}$のとき、独立である。さらに、$z^1_i(x)$は独立同分布から生成される項の和であるから、$N_1\rightarrow\infty$の極限でガウス分布に従う(中心極限定理)。その分布の平均値は以下のように計算される。 \begin{eqnarray} \mathbb{E}\left[z^1_i(x)\right]&=& \mathbb{E}\left[b_i^1+\sum_{j=1}^{N_{1}}W^1_{ij}x_j^1(x)\right]\\ &=& \mathbb{E}\left[b_i^1\right]+\mathbb{E}\left[\sum_{j=1}^{N_{1}}W^1_{ij}x_j^1(x)\right]\\ &=& \mathbb{E}_1\left[b_i^1\right]+\sum_{j=1}^{N_{1}}\mathbb{E}_1\left[W^1_{ij}\right]\mathbb{E}_0\left[x_j^1(x)\right] \end{eqnarray} ここで$\mathbb{E}_l[\cdot]$は$W^l,b^l$の量で期待値を取ることを意味する。式(\ref{eq1}),(\ref{eq2})から次式が成り立つ。 \begin{eqnarray} \mathbb{E}_1\left[b_i^1\right]&=&0\\ \mathbb{E}_1\left[W^1_{ij}\right]&=&0 \end{eqnarray} したがって \begin{equation} \mathbb{E}\left[z^1_i(x)\right]=0 \end{equation} である。分散は次式のようになる。 \begin{eqnarray} \mathbb{E}\left[z^1_i(x)z^1_i(x^{\prime})\right]&=&\mathbb{E}\left[\left(b_i^1+\sum_{j=1}^{N_{1}}W^1_{ij}x_j^1(x)\right)\left(b_i^1+\sum_{k=1}^{N_{1}}W^1_{ik}x_k^1(x^{\prime})\right)\right]\\ &=&\mathbb{E}_1\left[b^1_i b^1_i\right]+\sum_j^{N_1}\sum_k^{N_1}\mathbb{E}_1\left[W^1_{ij}W^1_{ik}\right]\mathbb{E}_0\left[x^1_j(x)x^1_k(x^{\prime})\right] \end{eqnarray} 式(\ref{eq1}),(\ref{eq2})から次式が成り立つ。 \begin{eqnarray} \mathbb{E}_1\left[b^1_i b^1_i\right]&=&\sigma_b^2\\ \mathbb{E}_1\left[W^1_{ij}W^1_{ik}\right]&=&\frac{\sigma^2_w}{N_1}\delta_{jk} \end{eqnarray} 故に \begin{eqnarray} \mathbb{E}\left[z^1_i(x)z^1_i(x^{\prime})\right] &=&\sigma^2_b+\sum_j^{N_1}\sum_k^{N_1}\delta_{jk}\frac{\sigma^2_w}{N_1}\mathbb{E}_0\left[x^1_j(x)x^1_k(x^{\prime})\right]\\ &=&\sigma^2_b+\frac{\sigma^2_w}{N_1}\sum_j^{N_1}\mathbb{E}_0\left[x^1_j(x)x^1_j(x^{\prime})\right]\\ &=&\sigma^2_b+\sigma^2_w\;C(x,x^{\prime}) \\ &\equiv&K^1(x,x^{\prime}) \end{eqnarray} を得る。ただし \begin{eqnarray} C(x,x^{\prime}) &=&\frac{1}{N_1}\sum_j^{N_1}\mathbb{E}_0\left[x^1_j(x)x^1_j(x^{\prime})\right]\\ &=&\frac{1}{N_1}\mathbb{E}_0\left[\sum_j^{N_1}x^1_j(x)x^1_j(x^{\prime})\right]\\ &=&\frac{1}{N_1}\mathbb{E}_0\left[x^1(x)^T\cdot x^1(x^{\prime})\right] \end{eqnarray} と置いた。いま入力ベクトル$x$が$N$個あるとする。これを${\bf x}=(x^{(1)},\cdots,x^{(N)})$と書くことにする。このとき$z_i^1(x)$も$N$個並べることができる。 \begin{equation} {\bf z}_i^1=(z_i^1(x^{(1)}),\cdots,z_i^1(x^{(N)})) \end{equation} この${\bf z}_i^1$が、$N_1\rightarrow\infty$のとき、ガウス分布$\mathcal{N}({\bf z}_i^1|{\bf 0},K^1)$に従う量と等価となる。そして、共分散行列$K^1$の成分$K^1_{nm}$が次式で与えられる。 \begin{equation} K^1_{nm}=K^1(x^{(n)},x^{(m)}) \end{equation} ${\bf 0}\in \mathbb{R}^N, K^1\in \mathbb{R}^{N\times N}$である。
同じようにして$z_i^0(x)$の平均値を求めると \begin{eqnarray} \mathbb{E}\left[z^0_i(x)\right]&=& \mathbb{E}\left[b_i^0+\sum_{k=1}^{d_{in}}W^0_{ik}x_k\right]\\ &=& \mathbb{E}\left[b_i^0\right]+\mathbb{E}\left[\sum_{k=1}^{d_{in}}W^0_{ik}x_k\right]\\ &=& \mathbb{E}_0\left[b_i^0\right]+\sum_{k=1}^{d_{in}}\mathbb{E}_0\left[W^0_{ij}\right]x_k\\ &=&0 \end{eqnarray} となり、分散は \begin{eqnarray} \mathbb{E}\left[z^0_i(x)z^0_i(x^{\prime})\right] &=&\mathbb{E}\left[\left(b_i^0+\sum_{k=1}^{d_{in}}W^0_{ik}x_k\right)\left(b_i^0+\sum_{j=1}^{d_{in}}W^0_{ij}x_j^{\prime}\right)\right]\\ &=&\mathbb{E}\left[b_i^0 b_i^0\right]+ \sum_{k=1}^{d_{in}}\sum_{j=1}^{d_{in}}\mathbb{E}_0\left[ W^0_{ik}W^0_{ij} \right]x_k x_j^{\prime}\\ &=& \sigma_b^2+ \sum_{k=1}^{d_{in}}\sum_{j=1}^{d_{in}} \frac{\sigma_w^2}{d_{in}}\delta_{kj} x_k x_j^{\prime}\\ &=& \sigma_b^2+ \frac{\sigma_w^2}{d_{in}}\sum_{k=1}^{d_{in}} x_k x_k^{\prime}\\ &=& \sigma_b^2+ \frac{\sigma_w^2}{d_{in}} x^T\cdot x^{\prime}\\ &\equiv&K^0(x,x^{\prime}) \end{eqnarray} となる。 すなわち、${\bf z}_i^0$は、ガウス分布$\mathcal{N}({\bf z}_i^0|{\bf 0},K^0)$に従う量となる
参考文献
Deep Neural Networks as Gaussian Processes
2018年11月6日火曜日
ベイズ推論とガウス過程
はじめに
ベイズ推論とガウス過程の関係を、回帰を例に取り確認する。
ベイズ線形回帰
まず最初にベイズ推論を用いて線形回帰を考察する。いま観測値$X$と$Y$が与えられているとする。 \begin{eqnarray} X&=&\{x_1,\cdots,x_N\},x_n\in \mathbb{R}^M \\ Y&=&\{y_1,\cdots,y_N\},\;y_n\in\mathbb{R} \end{eqnarray} このとき次の尤度を考える。 \begin{equation} p(y_n|x_n,w)=\mathcal{N}(y_n|w^T\phi(x_n),\beta^{-1}) \end{equation} ここで、$\mathcal{N}(y_n|\mu,\sigma^2)$は平均$\mu$、分散$\sigma^2$の正規分布を表す。$w$はパラメータ($w\in\mathbb{R}^D$)、$\phi(\cdot)$は$M$次元空間内の点を$D$次元空間内の点に射影する関数である。次に、$w$の事前分布を次のように導入する。 \begin{equation} p(w)=\mathcal{N}(w|0,\alpha^{-1}I_D) \end{equation} $I_D$は$D\times D$の単位行列である。このとき事後分布$p(w|X,Y)$は厳密に計算でき \begin{eqnarray} p(w|X,Y)&=&\mathcal{N}(w|m,S) \\ m&=&S\beta\Phi^Ty \in \mathbb{R}^D\\ S&=&(\alpha I_D+\beta\Phi^T\Phi)^{-1} \in \mathbb{R}^{D\times D} \end{eqnarray} を得る。$y=(y_1,\dots,y_N)^T$、$\Phi$は$\Phi_{nd}=\phi_d(x_n)$を成分に持つ$N\times D$行列である。さらに、この事後分布から予測分布を求めることができる。 \begin{eqnarray} p(y_{*}|x_{*},X,Y)&=&\mathcal{N}(y_{*}|m^T\phi(x_*),\sigma^2(x_*)) \label{eq1}\\ \sigma^2(x_*)&=&\beta^{-1}+\phi^T(x_*)S\phi(x_*) \end{eqnarray} 以上が、ベイズ推論による線形回帰の結果である。
ガウス過程による回帰
いま観測値$X$と$Y$が与えられているとする。 \begin{eqnarray} X&=&\{x_1,\cdots,x_N\},x_n\in \mathbb{R}^M \\ Y&=&\{y_1,\cdots,y_N\},\;y_n\in\mathbb{R} \end{eqnarray} 観測値$X$と$Y$の間には次の関係があるとする。 \begin{equation} y_n=z(x_n)+\epsilon_n \end{equation} $\epsilon_n$が正規分布に従うノイズであれば次の尤度を考えることができる。 \begin{equation} p(y_n|z_n)=\mathcal{N}(y_n|z_n,\beta^{-1}) \end{equation} ただし、$z_n=z(x_n)$とした。観測値は独立同分布から生成されると仮定すれば次式を得る。 \begin{eqnarray} p(y|z) &=&p(y_1,\dots,y_N|z_1,\cdots,z_N) \\ &=&\prod_{n=1}^N p(y_n|z_n) \\ &=&\prod_{n=1}^N \mathcal{N}(y_n|z_n,\beta^{-1}) \\ &=&\mathcal{N}(y|z,\beta^{-1}I_N) \end{eqnarray} ただし、$y=(y_1,\dots,y_N)^T$、$z=(z_1,\dots,z_N)^T$と置いた。$I_N$は$N\times N$の単位行列である。ここで、$z$がガウス過程から生成される量であると仮定すると、次の事前分布を使うことができる。 \begin{equation} p(z)=\mathcal{N}(z|0,K) \end{equation} 共分散行列$K$のサイズは$N\times N$であり、その成分は次式で定義される。 \begin{equation} K_{nm}=k(x_n,x_m) \end{equation} $k(x_n,x_m)$は2点から1つのスカラー量が決まる関数であり、カーネル関数と呼ばれる。これらを用いて、$p(y,z)$を$z$について周辺化する。 \begin{eqnarray} p(y)&=&\int dz\;p(y|z)\;p(z)\\ &=&\mathcal{N}(y|0,C) \end{eqnarray} $C$は$N\times N$の行列であり、その成分は次式で与えられる。 \begin{equation} C_{nm}=k(x_n,x_m)+\beta^{-1}\delta_{nm} \end{equation} 予測分布は次のようなる。 \begin{eqnarray} p(y_*|x_*,X,Y)&=&\mathcal{N}(y_*|m^{'}(x_*),\sigma^{'\;2}(x_*)) \label{eq2}\\ m^{'}(x_*)&=&k^TC^{-1}y \\ \sigma^{'\;2}(x_*)&=&c-k^TC^{-1}k \end{eqnarray} ただし \begin{eqnarray} k&=&(k(x_n,x_*),\cdots,k(x_N,x_*))^T \\ c&=&k(x_*,x_*)+\beta^{-1} \end{eqnarray} である。以上がガウス過程による回帰の結果である。
ベイズ推論とガウス過程の関係
いま、カーネル関数が次式で定義されるとする。 \begin{equation} k(x_n,x_m)=\alpha^{-1}\phi^T(x_n)\phi(x_m) \end{equation} このとき、式(\ref{eq1})と(\ref{eq2})は等しくなる。
ベイズ推論による解法では$D$次元空間を考えるが、ガウス過程による解法では$N$次元空間を考える。前者では$D\times D$行列の逆行列を、後者では$N\times N$行列の逆行列を計算する必要がある。それぞれの計算量は$\mathcal{O}(D^3)$と$\mathcal{O}(N^3)$である。$D\lt N$である場合、パラメータ空間で計算した方が計算量は少なくなる。ガウス過程を使う利点は、$K$として様々なカーネルを使うことができる点である。
ガウス過程のハイパーパラメータの決定
いま共分散行列$K$がハイパーパラメータ$\theta$でモデル化されているとする。 \begin{equation} p(z|\theta)=\mathcal{N}(z|0,K_{\theta}) \end{equation} このとき \begin{eqnarray} p(y|\theta)&=&\int dz\;p(y|z)\;p(z|\theta)\\ &=&\mathcal{N}(y|0,C_{\theta}) \\ C_{\theta,nm}&=&K_{\theta,nm}+\beta^{-1}\delta_{nm} \end{eqnarray} が成り立つ。事前分布$p(\theta)$を考えると次式が成り立つ。 \begin{equation} p(\theta|y)=\frac{p(y|\theta)p(\theta)}{p(y)} \end{equation} 一般的に右辺分母は解析的に計算できないので、何らかの近似が必要になる。書籍「Pythonによるベイズ統計モデリング PyMCでのデータ分析実践ガイド」の第8章にPyMC3を用いた解法が掲載されている。
2018年10月8日月曜日
ベルマン最適方程式とQ-LearningとDQN
はじめに
先の記事でベルマン最適方程式について書いた。今回は、この方程式とQ-Learningとを関連づけてみたい。最後にDQNについて少し言及する。
ベルマン最適方程式
行動価値関数に対するベルマン最適方程式は次式で与えられた。 \begin{equation} Q^{*}(s,a)=\sum_{s^{\prime}} P(s^{\prime}|s,a)\left[r(s,a,s^{\prime})+\gamma \max_{a^{\prime}}Q^{*}(s^{\prime},a^{\prime})\right] \label{eq1} \end{equation} ここで、$Q^{*}(s,a)$は最適行動価値関数、$s$と$a$はそれぞれ状態と行動を表す観測値を表す。$P(s^{\prime}|s,a)$は$(s,a)$が実現しているとき$s^{\prime}$が起こる確率、$r(s,a,s^{\prime})$は$(s,a,s^{\prime})$が実現するときの報酬を表す。$\gamma$は収益を定義するときに導入した割引率である。
Q-Learningとの関係
Q-Learningでは行動価値関数$Q(s,a)$を次式で更新していく。 \begin{equation} Q(s,a) \leftarrow (1-\alpha)Q(s,a)+\alpha\left[r(s,a,s^{\prime})+\gamma\max_{a^{\prime}}Q(s^{\prime},a^{\prime})\right] \label{eq3} \end{equation} ここで、$\alpha$は学習率である。現在の状態$s$とこの状態の下で選択した行動$a$から次の状態$s^{\prime}$ を決定論的に決めたあと、上式を用いて$Q(s,a)$を更新することに注意する。上式右辺を変形すると次式を得る。 \begin{equation} Q(s,a) \leftarrow Q(s,a)+\alpha\left[r(s,a,s^{\prime})+\gamma\max_{a^{\prime}}Q(s^{\prime},a^{\prime})-Q(s,a)\right] \end{equation} 更新を繰り返し$Q(s,a)$が収束したとき、上式右辺の第2項は0になるはずである。 \begin{equation} r(s,a,s^{\prime})+\gamma\max_{a^{\prime}}Q(s^{\prime},a^{\prime})-Q(s,a)=0 \end{equation} これより \begin{equation} Q(s,a)=r(s,a,s^{\prime})+\gamma\max_{a^{\prime}}Q(s^{\prime},a^{\prime}) \label{eq2} \end{equation} を得る。ここで、式(\ref{eq1})と式(\ref{eq2})を見比べて見ると、とても良く似ていることに気づく。違いは、式(\ref{eq1})では遷移確率$P(s^{\prime}|s,a)$が考慮されており、$s$の次に取り得る状態$s^{\prime}$について期待値が取られていることである。一方、式(\ref{eq2})では状態$s^{\prime}$は決定論的に決められる。
Deep Q Network(DQN)
Q-Learningでは式(\ref{eq3})を用いて$Q$を更新する。アルゴリズムの手順は以下のようなる。
- 現在の状態$s$が与えられる。
- 現在までに確定している$Q$値の表を見て、$s$のとき$Q$値を最大にする行動$a$を求める。ただし、ランダムに行動を選択する仕組みも取り入れ、他にあるかしれないより良い行動が見つかるようにする。
- $(s,a)$の下で次の状態$s^{\prime}$を決める。
- 現在までに確定している$Q$値の表を見て、$s^{\prime}$のとき最大となる$Q$値を求め、式(\ref{eq3})を用いて$Q$値を更新する。
参考文献
2018年8月5日日曜日
Adversarial Variational Bayes 〜理論(その2)〜
はじめに
前回の投稿では、論文Adversarial Variational Bayesの前半部分をまとめた。今回は後半部分をまとめる。
前半部分の結論
従来のVAEの目的関数は \begin{equation} (\theta^{*},\phi^{*})=\arg\max_{\theta,\phi} {\rm E}_{p_{d}(x)}\left[ -{\rm KL} \left( q_{\phi}(z|x), p(z) \right) + {\rm E}_{q_{\phi}(z|x)} \left[\ln{p_{\theta}(x|z)}\right] \right] \label{eq1} \end{equation} である。本論文の前半部分では式(\ref{eq1})から次の2つの目的関数を導出した。 \begin{eqnarray} T^{*}(x,z)&=&\arg{\max_{T}}\; {\rm E}_{p_{d}(x)} \left[ {\rm E}_{q_{\phi}(z|x)} \left[ \ln{\sigma\left(T(x, z)\right)} \right] + {\rm E}_{p(z)} \left[ \ln{\left(1-\sigma\left(T(x, z)\right)\right)} \right] \right] \label{eq2}\\ (\theta^{*},\phi^{*})&=&\arg\max_{\theta,\phi} {\rm E}_{p_{d}(x)}\;{\rm E}_{q_{\phi}(z|x)} \left[ \ln{p_{\theta}(x|z)}-T^{*}(x,z) \right] \label{eq3} \end{eqnarray} ここで、$\sigma(\cdot)$はシグモイド関数である。実際に計算を行うと、式(\ref{eq2})から最適な値$T^*(x,z)$を求めることは難しいことが分かる。その原因は、式(\ref{eq1})の右辺にあるKullback Leibler divergence にある。この量は、事後分布$q_{\phi}(z|x)$の形状を事前分布$p(z)$の形状に近づけようとする。一般にこれら2つの分布は大きく異なる形状を持つため、$q_{\phi}(z|x)\approx p(z)$の実現は難しい。また、事後分布を事前分布に近づける操作は、事後分布から観測値$x$の依存性を失くすことに相当するため、Bayes推論の立場から考えても妥当ではない。本論文の後半部分ではこの操作を改善する。
後半部分の内容
事後分布$q_{\phi}(z|x)$に良く似た形状を持ち、かつ、解析計算が可能な補助分布(auxiliary distribution)$r_{\alpha}(z|x)$を導入する。例えば、$r_{\alpha}(z|x)$として正規分布を考えることができる。この補助分布を用いて、式(\ref{eq1})の右辺を次のように書き換える。 \begin{equation} {\rm E}_{p_{d}(x)}\left[ -{\rm KL} \left( q_{\phi}(z|x), r_{\alpha}(z|x) \right) + {\rm E}_{q_{\phi}(z|x)} \left[ -\ln{r_{\alpha}(z|x)} +\ln{p_{\theta}(x,z)}\right] \right] \label{eq4} \end{equation} $r_{\alpha}(z|x)$を$q_{\phi}(z|x)$を近似する関数と置いたので、式(\ref{eq4})に現れるKullback Leibler divergenceの値は、式(\ref{eq1})のそれよりもずっと容易に小さな値とすることができる。
いま、補助分布として次の正規分布を仮定する。 \begin{equation} r_{\alpha}(z|x)=\mathcal{N}(z|\mu(x),\sigma_s^2(x)) \end{equation} これは、変数変換 \begin{equation} \tilde{z}=\frac{z-\mu(x)}{\sigma_s(x)} \end{equation} の下で \begin{equation} r_{\alpha}(z|x)=\frac{1}{\sigma_s}\mathcal{N}(\tilde{z}|0,1)\equiv \frac{1}{\sigma_s}r_0(\tilde{z}) \end{equation} となるから \begin{eqnarray} {\rm KL} \left( q_{\phi}(z|x), r_{\alpha}(z|x) \right) &=& \int dz\;q_{\phi}(z|x)\ln{\frac{q_{\phi}(z|x)}{r_{\alpha}(z|x)}} \label{eq5} \\ &=& \int d\tilde{z}\;\sigma_s q_{\phi}(\sigma_s \tilde{z}+\mu|x) \ln{ \frac {\sigma_s q_{\phi}(\sigma_s\tilde{z}+\mu|x)} {r_0(\tilde{z})} }\\ &=& {\rm KL} \left( \tilde{q}_{\phi}(\tilde{z}|x), r_0(\tilde{z}) \right) \label{eq6} \end{eqnarray} となる。ただし、$\tilde{q}_{\phi}(\tilde{z}|x)\equiv \sigma_s q_{\phi}(\sigma_s\tilde{z}+\mu|x)$とした。$\tilde{q}_{\phi}(\tilde{z}|x)$は \begin{equation} \int d\tilde{z}\tilde{q}_{\phi}(\tilde{z}|x)=1 \end{equation} を満たす新たな分布である。さらに、次式が成り立つ。 \begin{eqnarray} {\rm E}_{q_{\phi}(z|x)} \left[ \ln{r_{\alpha}(z|x)} \right] &=& \int dz\;q_{\phi}(z|x)\ln{r_{\alpha}(z|x)} \\ &=& \int d\tilde{z}\;\tilde{q}_{\phi}(\tilde{z}|x)\ln{r_{0}(\tilde{z})}-\ln{\sigma_s} \\ &=& {\rm E}_{\tilde{q}_{\phi}(\tilde{z}|x)} \left[ \ln{r_{0}(\tilde{z})} \right]+{\rm const.} \end{eqnarray} 以上から、式(\ref{eq4})は、定数項を無視して、次式に変換される。 \begin{equation} {\rm E}_{p_{d}(x)}\left[ -{\rm KL} \left( \tilde{q}_{\phi}(\tilde{z}|x), r_{0}(\tilde{z}) \right) + {\rm E}_{\tilde{q}_{\phi}(\tilde{z}|x)} \left[ -\ln{r_{0}(\tilde{z})} \right]+ {\rm E}_{q_{\phi}(z|x)} \left[ \ln{p_{\theta}(x,z)}\right] \right] \label{eq7} \end{equation} ここで、$-{\rm KL} \left( \tilde{q}_{\phi}(\tilde{z}|x), r_{0}(\tilde{z}) \right)$に注目して、論文の前半部分で用いた議論を繰り返し、$T(x,\tilde{z})$を導入すると、式(\ref{eq7})は次の2式と等価となる。 \begin{eqnarray} T^{*}(x,\tilde{z})&=&\arg{\max_{T}} \;{\rm E}_{p_{d}(x)} \left[ {\rm E}_{\tilde{q}_{\phi}(\tilde{z}|x)} \left[ \ln{\sigma\left(T(x, \tilde{z})\right)} \right] + {\rm E}_{r_0(\tilde{z})} \left[ \ln{\left(1-\sigma\left(T(x, \tilde{z})\right)\right)} \right] \right] \label{eq8}\\ (\theta^{*},\phi^{*}) &=& \arg\max_{\theta,\phi} \;{\rm E}_{p_{d}(x)} \left[ {\rm E}_{q_{\phi}(z|x)} \left[ \ln{p_{\theta}(x,z)} \right] + {\rm E}_{\tilde{q}_{\phi}(\tilde{z}|x)} \left[ -T^*(x,\tilde{z})-\ln{r_0(\tilde{z})} \right] \right] \label{eq9} \end{eqnarray} これらに、再パラメータ化トリックを適用する。すなわち、 \begin{equation} z\sim q_{\phi}(z|x) \end{equation} を \begin{eqnarray} \epsilon&\sim&p(\epsilon)\\ z&=&z_{\phi}(x,\epsilon) \end{eqnarray} に置き換える。このとき \begin{equation} \tilde{z}\sim \tilde{q}_{\phi}(\tilde{z}|x) \end{equation} は \begin{eqnarray} \tilde{z}&=&\frac{z_{\phi}(x,\epsilon)-\mu}{\sigma_s}\equiv\tilde{z}_{\phi}(x,\epsilon) \end{eqnarray} に置き換わる。また、分布$r_0(\tilde{z})$は標準正規分布であるから \begin{equation} \tilde{z} \sim r_0(\tilde{z}) \end{equation} は \begin{eqnarray} \eta&\sim&\mathcal{N}(\eta|0,1)\equiv p(\eta) \\ \tilde{z}&=&\eta \end{eqnarray} と書くことができる。以上から式(\ref{eq8}),(\ref{eq9})は次式に変形される。 \begin{eqnarray} T^{*}(x,\tilde{z}) &=& \arg{\max_{T}} \;{ \rm E}_{p_{d}(x)} \Bigl[ {\rm E}_{p(\epsilon)} \left[ \ln{\sigma\left(T(x, \tilde{z}_{\phi}(x,\epsilon))\right)} \right] + {\rm E}_{p(\eta)} \left[ \ln{\left(1-\sigma\left(T(x, \eta)\right)\right)} \right] \Bigr] \label{eq10}\\ (\theta^{*},\phi^{*}) &=& \arg\max_{\theta,\phi} \;{\rm E}_{p_{d}(x)} \Bigl[ {\rm E}_{p(\epsilon)} \left[ \ln{p_{\theta}(x,z_{\phi}(x,\epsilon))} \right] + {\rm E}_{p(\epsilon)} \left[ -T^*(x,\tilde{z}_{\phi}(x,\epsilon))-\ln{r_0(\tilde{z}_{\phi}(x,\epsilon))} \right] \Bigr] \label{eq11} \end{eqnarray} $r_0$は標準正規分布であるから、式(\ref{eq11})の最後の項は \begin{equation} -\ln{r_0(\tilde{z}_{\phi}(x,\epsilon))}=\frac{1}{2}\|\tilde{z}_{\phi}(x,\epsilon)\|^2+{\rm const.} \end{equation} となる。最適化を行う際は定数項は無視すれば良い。また、$p_{\theta}(x,z)$の計算は \begin{equation} p_{\theta}(x,z)=p_{\theta}(x|z)p(z) \end{equation} を利用すれば良い。ここまでの議論を反映したアルゴリズムが論文に掲載されている。

2018年7月1日日曜日
Adversarial Variational Bayes 〜理論と実装〜
はじめに
論文Adversarial Variational Bayesの前半部分の解説とChainerによる実装を行う。
論文概要
深層学習において生成モデルを求める代表的な手法は、Generative Adversarial Network(GAN)とVariational AutoEncoder(VAE)である。最初にGANが最適化する目的関数を示す。 \begin{equation} \min_{\theta}\max_{\phi} \left\{ {\rm E}_{p_{d}(x)}\left[\log{D_{\phi}(x)}\right]+{\rm E}_{p(z)}\left[1-\log{D_{\phi}\left(G_{\theta}(z)\right)}\right] \right\} \end{equation} ここで、$p_d(x)$と$p(z)$はそれぞれ観測値$x$と潜在変数$z$の分布を表す。 ${\rm E}_{p}\left[\cdot\right]$は分布$p$による期待値である。$D_{\phi}$は識別器、$G_{\theta}$は生成器であり、それぞれパラメータ$\phi$と$\theta$で象徴される重みを持つネットワークである。上の式は次の2つの最適化を行うことを表す。
- $\theta$を固定して考える。観測値$x$と生成器$G_{\theta}(z)$の出力値を識別器$D_{\phi}$に与えたとき、$D_{\phi}(x)$の値を最大にし、$D_{\phi}(G_{\theta}(z))$の値を最小にするような$\phi$を見つける。
- $\phi$を固定して考える。観測値$x$と生成器$G_{\theta}(z)$の出力値を識別器$D_{\phi}$に与えたとき、$D_{\phi}(x)$の値を最小にし、$D_{\phi}(G_{\theta}(z))$の値を最大にするような$\theta$を見つける。

GANを自然画像に適用すると、シャープな画像を生み出すが、VAEではボケた画像になることが知られている。これは、VAEの推論モデル$q_{\phi}(z|x)$が真の事後確率$p(z|x)$を再現できていないためである。今回紹介する文献は、任意の形状を持つ推論モデルを扱うことのできる手法(Adversarial Variational Bayes:AVB)を提案している。本文献の主張をまとめると次のようになる。
- 任意の複雑な推論モデルを扱うことができる。
- VAEの目的関数に数学的な変換を施すことによりGAN的な目的関数を導出する。すなわち、VAEに識別器に相当する量が導入される。
- 上の目的関数は、ある極限の下で、VAEの元の目的関数と厳密に一致する。
論文詳細
観測値$x$の分布$p(x)$を考え、潜在変数$z$を導入する。 \begin{eqnarray} \ln{p(x)} &=&\ln\int dz\;p(x|z)p(z) \\ &=&\ln\int dz\;q(z|x) \frac{p(x|z)p(z)}{q(z|x)} \end{eqnarray} Jensenの不等式を用いて \begin{eqnarray} \ln{p(x)} &\geqq&\int dz\;q(z|x) \ln\frac{p(x|z)p(z)}{q(z|x)} \\ &=&\int dz\;q(z|x)\ln{p(x|z)}-\int dz\;q(z|x)\ln{\frac{q(z|x)}{p(z)}} \\ &=&{\rm E}_{q(z|x)}\left[\ln{p(x|z)}\right]-{\rm KL}\left[q(z|x),p(z)\right] \\ &\equiv&\mathcal{L} \end{eqnarray} を得る。上式右辺はEvidence Lower Bound(ELOB)と呼ばれる量である。ここで、次の量を考える。 \begin{eqnarray} {\rm KL}\left(q(z|x),p(z|x)\right) &=&\int dz\;q(z|x)\ln{\frac{q(z|x)}{p(z|x)}} \\ &=&\int dz\;q(z|x)\ln{\frac{p(x)q(z|x)}{p(x,z)}} \\ &=&\int dz\;q(z|x)\ln{\frac{p(x)q(z|x)}{p(x|z)p(z)}} \\ &=&\int dz\;q(z|x)\ln{p(x)}-\int dz\;q(z|x)\ln{p(x|z)}+{\rm KL}(q(z|x),p(z)) \\ &=&\ln{p(x)}-\int dz\;q(z|x)\ln{p(x|z)}+{\rm KL}(q(z|x),p(z)) \\ \end{eqnarray} 上式は先に定義したELBO($\mathcal{L}$)を用いると \begin{equation} {\rm KL}\left(q(z|x),p(z|x)\right)=\ln p(x)-\mathcal{L} \end{equation} と書くことができる。すなわち次式が成り立つ。 \begin{equation} \ln p(x)=\mathcal{L}+{\rm KL}\left(q(z|x),p(z|x)\right) \end{equation} $q(z|x)$は分布$p(z|x)$を近似するために導入された分布であり、パラメータ$\phi$を持つとする。一方、分布$p(x|z)$を表現するモデルはパラメータ$\theta$を持つとする。これらパラメータを顕に書くと \begin{eqnarray} \ln p(x)&=&\mathcal{L}+{\rm KL}\left(q_{\phi}(z|x),p(z|x)\right) \label{eq2}\\ \ln p(x)&\geqq&\mathcal{L} \label{eq1}\\ \mathcal{L}&=&{\rm E}_{q_{\phi}(z|x)}\left[\ln{p_{\theta}(x|z)}\right]-{\rm KL}\left[q_{\phi}(z|x),p(z)\right] \end{eqnarray} となる。VAEでは式(\ref{eq1})の右辺を$\phi$と$\theta$について最大化する。式(\ref{eq2})から、$\ln p(x)=\mathcal{L}$が成り立つのは$q_{\phi}(z|x)=p(z|x)$となる時であることが分かるが、一般にこの等式が成り立つことはない。通常のVAEでは実際に計算を進める際、$q_{\phi}(z|x)$を正規分布で近似する。本文献では$q_{\phi}(z|x)$に対してそのような近似を行わない。
$\mathcal{L}$は以下のように書き換えることができる。 \begin{eqnarray} \mathcal{L} &=&{\rm E}_{q_{\phi}(z|x)}\left[\ln{p_{\theta}(x|z)}\right]-{\rm KL}\left[q_{\phi}(z|x),p(z)\right] \\ &=&{\rm E}_{q_{\phi}(z|x)}\left[\ln{p_{\theta}(x|z)}\right]-\int dz\;q_{\phi}(z|x)\ln{\frac{q_{\phi}(z|x)}{p(z)}} \\ &=&{\rm E}_{q_{\phi}(z|x)}\left[\ln{p_{\theta}(x|z)}\right]-\int dz\;q_{\phi}(z|x) \left[ \ln{q_{\phi}(z|x)}-\ln{p(z)} \right] \\ &=&{\rm E}_{q_{\phi}(z|x)} \left[ \ln{p_{\theta}(x|z)}-\ln{q_{\phi}(z|x)}+\ln{p(z)} \right]\\ \end{eqnarray} 従って、VAEの目的関数は \begin{equation} \max_{\theta}\max_{\phi} {\rm E}_{q_{\phi}(z|x)} \left[ \ln{p_{\theta}(x|z)}-\ln{q_{\phi}(z|x)}+\ln{p(z)} \right] \label{eq4} \end{equation} となる。ここまでは通常のVAEである。本文献では、ここで、関数$T^*(x,z)$を次式で導入する。 \begin{equation} T^*(x,z)=\arg\max_{T} \left\{ {\rm E}_{q_{\phi}(z|x)} \left[ \ln{\sigma\left(T(x, z)\right)} \right] + {\rm E}_{p(z)} \left[ \ln{\left(1-\sigma\left(T(x, z)\right)\right)} \right] \right\} \label{eq3} \end{equation} この式は、$q_{\phi}(z|x)$からサンプリングされた$z$のとき$T(x,z)$を大きくし、$p(z)$からサンプリングされた$z$のとき$T(x,z)$を小さくすることを意味する。すなわち、$T(x,z)$は$q_{\phi}(x|z)$と$p(z)$を識別する識別器である。実際に$T^*(x,z)$を求めるため、式(\ref{eq3})の期待値を積分に書き換える。 \begin{equation} \int dz \left[ q_{\phi}(z|x) \ln{\sigma\left(T(x, z)\right)} + p(z) \ln{\left(1-\sigma\left(T(x, z)\right)\right)} \right] \end{equation} 上式の被積分関数の最大値を求めるため、$a=q_{\phi}(z|x)$、$b=p(z)$、$t=\sigma\left(T(x,z)\right)$として次式を考える。 \begin{equation} y=a\ln{t}+b\ln{(1-t)} \end{equation} 両辺$t$で微分して \begin{equation} \frac{dy}{dt}=\frac{a}{t}-\frac{b}{1-t} \end{equation} 右辺を0とおいて \begin{equation} t=\frac{a}{a+b} \end{equation} を得る。各変数を元に戻して計算すると \begin{equation} T(x,z)=\ln{q_{\phi}(z|x)}-\ln{p(z)}\equiv T^{*}(x,z) \end{equation} を得る。$T^{*}$を用いると、式(\ref{eq4})は以下のように書くことができる。 \begin{equation} \max_{\theta}\max_{\phi} {\rm E}_{q_{\phi}(z|x)} \left[ \ln{p_{\theta}(x|z)}-T^{*}(x,z) \right] \label{eq5} \end{equation} ただし \begin{equation} T^{*}(x,z)=\arg{\max_{T}} \left\{ {\rm E}_{q_{\phi}(z|x)} \left[ \ln{\sigma\left(T(x, z)\right)} \right] + {\rm E}_{p(z)} \left[ \ln{\left(1-\sigma\left(T(x, z)\right)\right)} \right] \right\} \label{eq6} \end{equation} である。式(\ref{eq5})と(\ref{eq6})に再パレメータ化トリックを用いると \begin{eqnarray} T^{*}(x,z)&=&\arg{\max_{T}} \left\{ {\rm E}_{p(\epsilon)} \left[ \ln{\sigma\left(T(x, z_{\phi}(x,\epsilon)\right)} \right] + {\rm E}_{p(z)} \left[ \ln{\left(1-\sigma\left(T(x, z)\right)\right)} \right] \right\} \\ (\theta^*,\phi^*)&=&\arg\max_{\theta,\phi} {\rm E}_{p(\epsilon)} \left[ \ln{p_{\theta}\left(x|z_{\phi}\left(x,\epsilon\right)\right)}-T^{*}\left(x,z_{\phi}\left(x,\epsilon\right)\right) \right] \label{eq7} \end{eqnarray} を得る。$p(\epsilon)$は標準正規分布とすれば良い。観測値の分布$p_d(x)$による期待値も考慮して最終的に次の2つの目的関数を考えることになる。 \begin{eqnarray} T^{*}(x,z)&=&\arg{\max_{T}} \left\{ {\rm E}_{p_d(x)} {\rm E}_{p(\epsilon)} \left[ \ln{\sigma\left(T(x, z_{\phi}(x,\epsilon)\right)} \right] + {\rm E}_{p_d(x)} {\rm E}_{p(z)} \left[ \ln{\left(1-\sigma\left(T(x, z)\right)\right)} \right] \right\} \label{eq9}\\ (\theta^*,\phi^*)&=&\arg\max_{\theta,\phi} {\rm E}_{p_d(x)}{\rm E}_{p(\epsilon)} \left[ \ln{p_{\theta}\left(x|z_{\phi}\left(x,\epsilon\right)\right)}-T^{*}\left(x,z_{\phi}\left(x,\epsilon\right)\right) \right] \label{eq8} \end{eqnarray} 上の2式が本文献の最初の手法である。$T$を最適化したあと$(\theta,\phi)$を最適化する。アルゴリズムが文献に掲載されている。

- $z_{\phi}(x,\epsilon)$
- $p_{\theta}(x|z)$のパラメータ
- $T_{\psi}(x,z)$



Chainerによる実装
ここからは、Chainerを用いて実際に実装を行い、上の図5に示された実験データから図6(b)の結果を再現するまでの様子を記載する。ソースコードはここにある。既存の実装として参考にしたのは以下の3つである。
- https://gist.github.com/poolio/b71eb943d6537d01f46e7b20e9225149
- https://github.com/gdikov/adversarial-variational-bayes
- https://github.com/LMescheder/AdversarialVariationalBayes
Encoder
まず最初にEncoder($z_{\phi}(x,\epsilon)$)の実装を示す(encoder.py内のコードである)。
class Encoder_2(chainer.Chain):
def __init__(self, x_dim, eps_dim, h_dim=512):
super(Encoder_2, self).__init__()
with self.init_scope():
self.l1 = L.Linear(x_dim + eps_dim, h_dim, initialW=xavier.Xavier(x_dim + eps_dim, h_dim))
self.l2 = L.Linear(h_dim, h_dim, initialW=xavier.Xavier(h_dim, h_dim))
self.l3 = L.Linear(h_dim, h_dim, initialW=xavier.Xavier(h_dim, h_dim))
self.l4 = L.Linear(h_dim, eps_dim, initialW=xavier.Xavier(h_dim, eps_dim))
def update(self, updates):
update_links(self, updates)
def __call__(self, xs, es, activation=F.relu):
xs = 2 * xs - 1
h = F.concat((xs, es), axis=1)
h = self.l1(h)
h = activation(h)
h = self.l2(h)
h = activation(h)
h = self.l3(h)
h = activation(h)
h = self.l4(h)
return h
- 入力値は観測値xsと標準正規分布からのサンプル値esである。
- 15行目:xsは0と1である。これを-1と1に置き換える。
- 16行目:xsとesを連結する。
- あとは、全結合層と活性化関数の繰り返しである。
- 出力層には活性化関数を適用しない。
- 活性化関数としてreluを採用した。
Decoder
次はDecoderである(decoder.py内のコードである)。実験データは0と1から構成されるので$p_{\theta}(x|z)$としてBernoulli分布を用いる。 \begin{eqnarray} p_{\theta}(x|z) &=&{\rm Bern}(x|\mu(z))\\ &=&\mu(z)^x(1-\mu(z))^{1-x} \end{eqnarray} Decoderはパラメータ$\mu(z)$を計算する。
class Decoder_1(chainer.Chain):
def __init__(self, z_dim, x_dim=1, h_dim=512):
super(Decoder_1, self).__init__()
with self.init_scope():
self.l1 = L.Linear(z_dim, h_dim, initialW=xavier.Xavier(z_dim, h_dim))
self.l2 = L.Linear(h_dim, h_dim, initialW=xavier.Xavier(h_dim, h_dim))
self.l3 = L.Linear(h_dim, h_dim, initialW=xavier.Xavier(h_dim, h_dim))
self.l4 = L.Linear(h_dim, x_dim, initialW=xavier.Xavier(h_dim, x_dim))
def update(self, updates):
update_links(self, updates)
def __call__(self, zs, activation=F.tanh, is_sigmoid=False):
h = self.l1(zs)
h = activation(h)
h = self.l2(h)
h = activation(h)
h = self.l3(h)
h = activation(h)
h = self.l4(h)
if is_sigmoid:
h = F.sigmoid(h)
return h
- 入力値は潜在変数zsである。
- 最終層にだけ仕掛けがしてある。訓練時はis_sigmoid=False、テスト時にはis_sigmoid=Trueとする。
Discriminator
次はDiscriminator($T_{\psi}(x,z)$)である(discriminator.py)。
class Discriminator_1(chainer.Chain):
def __init__(self, x_dim, z_dim, h_dim=512):
super(Discriminator_1, self).__init__()
self.h_dim = h_dim
with self.init_scope():
self.xl1 = L.Linear(x_dim, h_dim, initialW=xavier.Xavier(x_dim, h_dim))
self.xl2 = L.Linear(h_dim, h_dim, initialW=xavier.Xavier(h_dim, h_dim))
self.xl3 = L.Linear(h_dim, h_dim, initialW=xavier.Xavier(h_dim, h_dim))
self.zl1 = L.Linear(z_dim, h_dim, initialW=xavier.Xavier(z_dim, h_dim))
self.zl2 = L.Linear(h_dim, h_dim, initialW=xavier.Xavier(h_dim, h_dim))
self.zl3 = L.Linear(h_dim, h_dim, initialW=xavier.Xavier(h_dim, h_dim))
def update(self, updates):
update_links(self, updates)
def __call__(self, xs, zs, activation=F.relu):
xs = 2 * xs - 1
hx = self.xl1(xs)
hx = activation(hx)
hx = self.xl2(hx)
hx = activation(hx)
hx = self.xl3(hx)
hx = activation(hx)
hz = self.zl1(zs)
hz = activation(hz)
hz = self.zl2(hz)
hz = activation(hz)
hz = self.zl3(hz)
hz = activation(hz)
h = F.sum(hx * hz, axis=1) / self.h_dim
return h
- 入力値は観測値xsと潜在変数zsである。
- 18行目:xsは0と1である。これを-1と1に置き換える。
- 19行目から24行目:xsについての計算である。
- 26行目から31行目:zsについての計算である。
- 32行目:それぞれの結果の内積を取る。
$(\theta,\phi)$についての目的関数(式(\ref{eq8}))
式(\ref{eq8})を実装したものが以下である(phi_loss_calculator.py)。
class PhiLossCalculator_2(chainer.Chain):
def __init__(self, encoder, decoder, discriminator):
super(PhiLossCalculator_2, self).__init__()
with self.init_scope():
self.encoder = encoder
self.decoder = decoder
self.discriminator = discriminator
def __call__(self, xs, zs, es):
batch_size = xs.shape[0]
encoded_zs = self.encoder(xs, es)
ys = self.decoder(encoded_zs)
d_loss = F.bernoulli_nll(xs, ys) / batch_size
t_loss = F.sum(self.discriminator(xs, encoded_zs)) / batch_size
return t_loss + d_loss, encoded_zs
- 式(\ref{eq8})では最大化しているが、実装では符号を反転させて最小化させる。
$\psi$についての目的関数(式(\ref{eq9}))
式(\ref{eq9})を実装したものが以下である(psi_loss_calculator.py)。
class PsiLossCalculator_3(chainer.Chain):
def __init__(self, encoder, discriminator):
super(PsiLossCalculator_3, self).__init__()
with self.init_scope():
self.encoder = encoder
self.discriminator = discriminator
def __call__(self, xs, zs, es):
# batch_size = xs.shape[0]
encoded_zs = self.encoder(xs, es)
posterior = self.discriminator(xs, encoded_zs)
prior = self.discriminator(xs, zs)
a = F.sigmoid_cross_entropy(posterior, np.ones_like(posterior).astype(np.int32))
b = F.sigmoid_cross_entropy(prior, np.zeros_like(prior).astype(np.int32))
c = F.sum(a + b)
return c
- こちらの目的関数も符号を反転させて最小化させる。
訓練コード
訓練コードの一部を掲載する。
for epoch in range(args.epochs):
with chainer.using_config('train', True):
# shuffle dataset
sampler.shuffle_xs()
epoch_phi_loss = 0
epoch_psi_loss = 0
for i in range(batches):
xs = sampler.sample_xs()
zs = sampler.sample_zs()
es = sampler.sample_es()
# compute psi-gradient(eq.3.3)
update_switch.update_models(enc_updates=False, dec_updates=False,
dis_updates=True)
psi_loss = psi_loss_calculator(xs, zs, es)
update(psi_loss, psi_loss_calculator, psi_optimizer)
epoch_psi_loss += psi_loss
# compute phi-gradient(eq.3.7)
update_switch.update_models(enc_updates=True, dec_updates=True,
dis_updates=False)
phi_loss, _ = phi_loss_calculator(xs, zs, es)
update(phi_loss, phi_loss_calculator, phi_optimizer)
epoch_phi_loss += phi_loss
# end for ...
# see loss per epoch
epoch_phi_loss /= batches
epoch_psi_loss /= batches
# end with ...
print('epoch:{}, phi_loss:{}, psi_loss:{}'.format(epoch, epoch_phi_loss.data,
epoch_psi_loss.data))
epoch_phi_losses.append(epoch_phi_loss.data)
epoch_psi_losses.append(epoch_psi_loss.data)
# end for ...
- 文献に掲載されているアルゴリズム図をほぼ踏襲している。
- 15行目から19行目:目的関数(\ref{eq9})を更新する。その際、EncoderとDecoderの重みを固定する(15行目)。
- 22行目から26行目:目的関数(\ref{eq8})を更新する。その際、Discriminatorの重みを固定する(22行目)。
予測のためのコード
訓練後に実行するコートはpredict.pyである。掲載は略。
実行
次を実行する。
$> ./train.py
$> ./predict.py
結果
結果の表示はvisualize.ipynbで行った。最初に式(\ref{eq9})と(\ref{eq8})の変化を示す。


まとめ
論文Adversarial Variational Bayesの前半部分の解説と実装を示した。正直なところ、上のような形に到達するまでかなりの時間を費やして試行錯誤を繰り返した。2つの目的関数を交互に最適化するのは大変難しい。ご批判いただければ幸いである。
2018年5月2日水曜日
Variational Auto Encoder 〜その3〜
はじめに
先のページで、Variational Auto Encoder(VAE)を実装したChainerのサンプルコードをそのまま動かし、生成される画像を見た。符号化・復号化して得られる画像は、入力画像をそれなりに再現していたが、乱数から生成される画像は精度が良くないことを示した。今回は、サンプルコードに手を加えて実験を行う。
ソースコードの場所
今回のソースコードはここにある。
評価基準
このページで示したように、勾配降下法で最適化すべき式は次式である。 \begin{equation} \min_{\phi} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}|X) \right] = \min_{\phi} {\left[ D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]-E_{q_{\phi}(\vec{z}|X)}\left[\ln{p(X|\vec{z})}\right] \right] } \end{equation} この右辺第1項は次のように書けた。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]= \frac{1}{2} \sum_{d=1}^{D}\left\{ -\ln{\sigma^2_{\phi,d}(X)}-1+\sigma^2_{\phi,d}(X)+\mu_{\phi,d}^2(X) \right\} \label{eq1} \end{equation} また、潜在変数$\vec{z}$の成分は次式で与えられた。 \begin{equation} z_d=\mu_{\phi,d}(X)+\sigma_{\phi,d}(X)\epsilon_d \end{equation} 式(\ref{eq1})で理想的な最適化を実現できれば、$\mu_{\phi,d}(X)\rightarrow 0,\sigma_{\phi,d}(X)\rightarrow 1$とできる。このとき、$\vec{z}$は標準正規分布から生成される値$\vec{\epsilon}$に置き換えることができる。net.py内にある関数decodeは本来ならば$\vec{z}$を与えて画像を生成するコードであるが、実際に使われる際は標準正規分布から作られる値を与えている。従って、上記の収束が不十分であると、意図した振る舞いをしないことになる。最適化を行う際に、$\mu_{\phi,d}(X)$と$\sigma_{\phi,d}(X)$の値の変化も追跡すべきである。以上の考察に基づきnet.pyに実装されている関数get_loss_funcを以下のように変更した。
def get_loss_func(self, C=1.0, k=1):
"""Get loss function of VAE.
The loss value is equal to ELBO (Evidence Lower Bound)
multiplied by -1.
Args:
C (int): Usually this is 1.0. Can be changed to control the
second term of ELBO bound, which works as regularization.
k (int): Number of Monte Carlo samples used in encoded vector.
"""
def lf(x):
mu, ln_var = self.encode(x)
mean_mu, mean_sigma = calculate_means(mu, ln_var)
batchsize = len(mu.data)
# reconstruction loss
rec_loss = 0
for l in six.moves.range(k):
z = F.gaussian(mu, ln_var)
rec_loss += F.bernoulli_nll(x, self.decode(z, sigmoid=False)) \
/ (k * batchsize)
self.rec_loss = rec_loss
kl = gaussian_kl_divergence(mu, ln_var) / batchsize
self.loss = self.rec_loss + C * kl
chainer.report(
{
'rec_loss': rec_loss,
'loss': self.loss,
'kl': kl,
'mu': mean_mu,
'sigma': mean_sigma,
},
observer=self)
return self.loss
return lf
12行目でmuとsigmaの平均値を計算している。これに伴い、実行中にコマンドラインに表示する項目を増やしている( 25行目から29行目)。関数calculate_meansの中身は以下の通りである。
def calculate_means(mu, ln_var):
xp = chainer.cuda.get_array_module(mu)
mean_mu = xp.mean(mu.data)
sigma = xp.exp(ln_var.data / 2)
mean_sigma = xp.mean(sigma)
return mean_mu, mean_sigma
実験-1
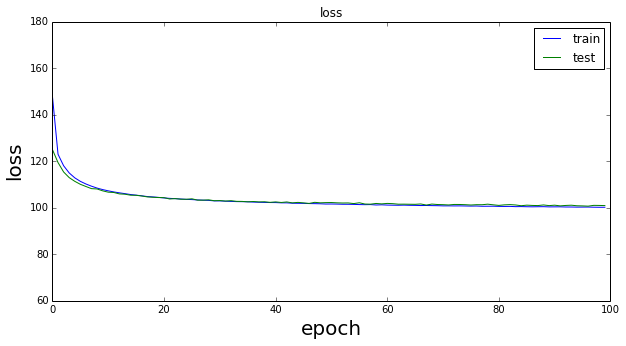
先のページと同じパラメータ(epoch=100,dimz=20)で実行したときのmuとsigmaの変化は以下の通りである。
mu

sigma
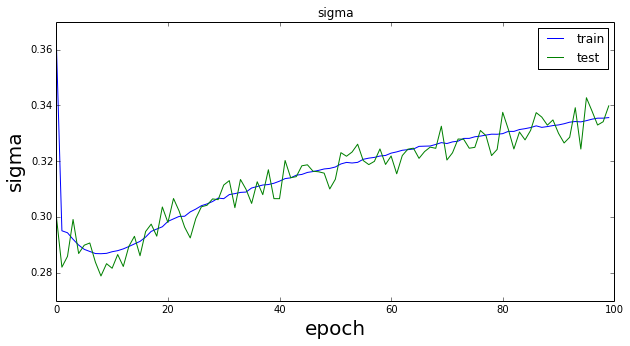
訓練データに対するmuの値は0近傍を推移しているがepochの後半部分で振動しており、テストデータに対するそれは終始振動していることが分かる。sigmaの方は1からは程遠い値である。このときのトータルのlossは以下のようになる。
loss
実験-2
次に、こちらで紹介されている実装で実験を行った。ソースコード内にnet_2.pyとして保存してある。epoch=100、dimz=100とした結果を以下に示す。
mu

sigma

muもsigmaもかなり改善されていることが分かる。muは0に、sigmaは1に近づいている。このときのトータルのlossは以下のようになる。
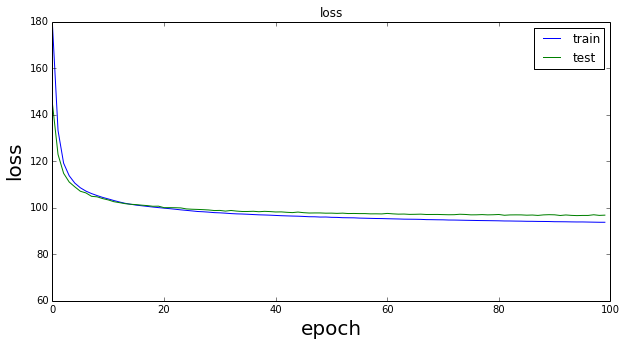
こちらも少しだけ改善されている。
生成画像の比較
実験-1と2で、標準正規分布から生成した同じ乱数値から復号された画像を示す。
実験-1
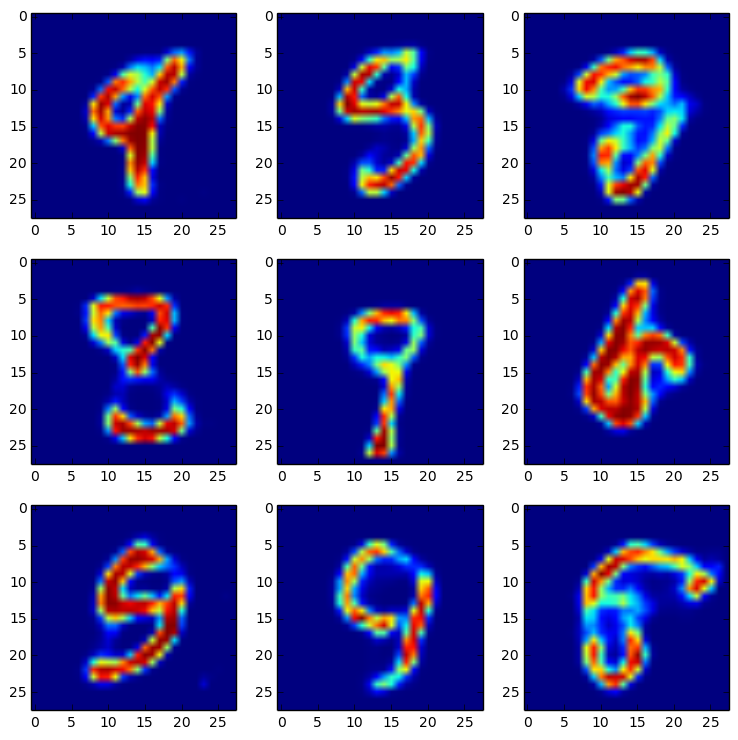
実験-2

後者の方が数字であることを判別できるので精度は良くなっている(と思う)。
まとめ
今回は、Chainerのサンプルコードに手を加えて実験を行った。muは0に、sigmaは1に近い方が復号化される画像の精度も上がることを示した。VAEを使用する場合、lossだけでなく、muやsigmaの値の推移も確認した方が良い。
2018年4月27日金曜日
Conditional Variational Auto Encoder
はじめに
先の2回の投稿(こことここ)では、Variational Auto Encoder(VAE)をBayes推論の枠組みで解説した。今回は、Conditional Variational Auto Encoder(CAVE)をBayes推論の枠組みで説明する。
問題設定
回帰問題を考え、$N$個のペア$(\vec{x}_n, \vec{y}_n)$が観測されているとする。$X=\{\vec{x}_1,\cdots,\vec{x}_N\}, Y=\{\vec{y}_1,\cdots,\vec{y}_N\}$と置いたとき、未観測データ$\vec{x}_{\alpha}$に対応する$\vec{y}_{\alpha}$を生成する確率分布$p(\vec{y}_{\alpha}|\vec{x}_{\alpha},X,Y)$を求めたい。潜在変数$\vec{z}$を導入し、$X$、$Y$、$\vec{z}$の同時確率分布$p(X,Y,\vec{z})$を考え、Bayesの定理を適用すると次式を得る。 \begin{equation} p(\vec{z}|X,Y) = \frac{p(Y|X,\vec{z})p(\vec{z})}{p(Y|X)} \label{eq9} \end{equation} ただし、式変形の途中で$p(X|\vec{z})=p(X)$を用いた。事後確率$p(\vec{z}|X,Y)$が求まれば、次式により$\vec{y}_{\alpha}$を生成する確率分布を求めることができる。 \begin{equation} p(\vec{y}_{\alpha}|\vec{x}_{\alpha},X,Y)=\int d\vec{z}\;p(\vec{y}_{\alpha}|\vec{x}_{\alpha},\vec{z})p(\vec{z}|X,Y) \label{eq3} \end{equation} 事後確率$p(\vec{z}|X,Y)$を求めることが目的である。
最適化すべき量
$p(\vec{z}|X,Y)$を直接求めることはせず、パラメータ$\phi$を持つ関数$q_{\phi}(\vec{z}|X,Y)$を導入し、次のKullback Leibler divergenceを最小にすることを考える。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}|X,Y) \right]=\int d\vec{z}\;q_{\phi}(\vec{z}|X,Y) \ln{ \frac{ q_{\phi}(\vec{z}|X,Y) } { p(\vec{z}|X,Y) } } \end{equation} これを変形すると次式を得る。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}|X,Y) \right] = D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}) \right]-E_{q_{\phi}(\vec{z}|X,Y)}\left[\ln{p(Y|X,\vec{z})}\right]+\ln{p(Y|X)} \label{eq1} \end{equation} ただし、式変形の途中で式(\ref{eq9})を用いた。式(\ref{eq1})右辺にある$\ln{p(Y|X)}$は$\phi$に依存せず、観測値だけから決まる定数である。従って、次式が成り立つ。 \begin{equation} \min_{\phi} D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}|X,Y) \right] = \min_{\phi} {\left[ D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}) \right]-E_{q_{\phi}(\vec{z}|X,Y)}\left[\ln{p(Y|X,\vec{z})}\right] \right] } \label{eq2} \end{equation} 式(\ref{eq2})の右辺第1項を小さく、第2項の期待値を大きくすれば良い。第1項は$q_{\phi}(\vec{z}|X,Y)$をできるだけ$p(\vec{z})$に近い形の分布にすることを要求し、この分布の下で対数尤度$\ln{p(Y|X,\vec{z})}$の期待値を大きくすることを第2項は要求する。第1項は正則化項に相当する。
KL divergenceの計算
式(\ref{eq2})の右辺第1項を考える。いま次の仮定をおく。 \begin{eqnarray} q_{\phi}(\vec{z}|X,Y)&=&\mathcal{N}(\vec{z}|\vec{\mu}_{\phi}(X,Y),\Sigma_{\phi}(X,Y)) \\ p(\vec{z})&=&\mathcal{N}(\vec{z}|\vec{0},I_D) \end{eqnarray} ここで、$\vec{z}$の次元を$D$とした。$I_D$は$D\times D$の単位行列である。どちらの分布も正規分布とし、$q_{\phi}(\vec{z}|X,Y)$の平均と共分散行列は$\phi,X,Y$から決まる量とする。これらは、入力$X,Y$、パラメータ$\phi$のニューラルネットワークを用いて計算される。一方、$p(\vec{z})$の方は平均0、分散1の標準正規分布である。このとき、$D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}) \right]$は解析的に計算することができる。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}) \right]=\frac{1}{2}\left[ -\ln{|\Sigma_{\phi}(X,Y)|} -D +\mathrm{Tr}\left(\Sigma_{\phi}(X,Y)\right)+\vec{\mu}_{\phi}(X,Y)^T\vec{\mu}_{\phi}(X,Y) \right] \label{eq4} \end{equation}
ここまでの処理の流れ
式(\ref{eq2})を計算する際の手順は以下のようになる。

分布$q_{\phi}(\vec{z}|X,Y)$は$X$と$Y$から$\vec{z}$を生成するEncoder、$p(Y|X,\vec{z})$は$X$と$\vec{z}$から$Y$を生成するDecoderとみなすことができる。青色で示した部分は最小化すべき量であり、赤字はサンプリングするステップである。青色の式の和を勾配降下法により最小にするが、その際、誤差逆伝播ができなければならない。$q_{\phi}(\vec{z}|X,Y)$はその$\phi$依存性のため誤差逆伝播時の微分鎖の中に組み込まれるが、サンプリングという処理の勾配を定義することができない。対数尤度の期待値の計算に工夫が必要である。
対数尤度の期待値の計算
計算したい式は次式である。 \begin{equation} E_{q_{\phi}(\vec{z}|X,Y)}\left[\ln{p(Y|X,\vec{z})}\right]=\int d\vec{z}\;q_{\phi}(\vec{z}|X,Y)\ln{p(Y|X,\vec{z})} \end{equation} この式に再パラメータ化トリック(re-parametrization trick)を適用する。すなわち \begin{equation} \vec{z}\sim\mathcal{N}(\vec{z}|\vec{\mu}_{\phi}(X,Y),\Sigma_{\phi}(X,Y)) \end{equation} の代わりに \begin{eqnarray} \vec{\epsilon}&\sim&\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\\ \vec{z}&=& \vec{\mu}_{\phi}(X,Y)+\Sigma_{\phi}^{1/2}(X,Y)\vec{\epsilon} \label{eq7} \end{eqnarray} を用いてサンプリングを行う。これを用いて期待値を書き直すと次式を得る。 \begin{equation} E_{q_{\phi}(\vec{z}|X,Y)}\left[\ln{p(Y|X,\vec{z})}\right]=\int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\ln{p(Y|X, \vec{z}=\vec{\mu}_{\phi}(X,Y)+\Sigma_{\phi}^{1/2}(X,Y)\vec{\epsilon})} \label{eq11} \end{equation} 処理の流れは以下のように変更される。

上図であれば誤差逆伝播が可能となる。
未観測データの生成
未観測データ$\vec{y}_{\alpha}$を生成する確率分布は次式で与えられた。 \begin{equation} p(\vec{y}_{\alpha}|\vec{x}_{\alpha},X,Y)=\int d\vec{z}\;p(\vec{y}_{\alpha}|\vec{x}_{\alpha},\vec{z})p(\vec{z}|X,Y) \end{equation} 事後確率$p(\vec{z}|X,Y)$の近似解$q_{\phi}(\vec{z}|X,Y)$を用いると \begin{equation} p(\vec{y}_{\alpha}|\vec{x}_{\alpha},X,Y)\approx\int d\vec{z}q_{\phi}(\vec{z}|X,Y)p(\vec{y}_{\alpha}|\vec{x}_{\alpha},\vec{z}) \end{equation} を得る。先と同様に再パラメータ化トリックを適用すると \begin{equation} p(\vec{y}_{\alpha}|\vec{x}_{\alpha},X,Y)\approx\int d\vec{\epsilon}\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)p(\vec{y}_{\alpha}|\vec{x}_{\alpha}, \vec{z}=\vec{\mu}_{\phi}(X,Y)+\Sigma_{\phi}^{1/2}(X,Y)\vec{\epsilon}) \label{eq10} \end{equation} となる。
実装に向けた詳細な計算
最初に$\vec{\mu}_{\phi}(X,Y)$と$\Sigma_{\phi}(X,Y)$を次のように置く。 \begin{eqnarray} \vec{\mu}_{\phi}(X,Y)&=&(\mu_{\phi,1}(X,Y),\cdots,\mu_{\phi,D}(X,Y))^T \label{eq5}\\ \Sigma_{\phi}(X,Y)&=&\mathrm{diag}(\sigma^2_{\phi,1}(X,Y),\cdots,\sigma^2_{\phi,D}(X,Y)) \label{eq6} \end{eqnarray} このとき式(\ref{eq4})は次式となる。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}) \right]= \frac{1}{2} \sum_{d=1}^{D}\left\{ -\ln{\sigma^2_{\phi,d}(X,Y)}-1+\sigma^2_{\phi,d}(X,Y)+\mu_{\phi,d}^2(X,Y) \right\} \label{eq8} \end{equation} また、$\vec{z}$の成分は次式で与えられる。 \begin{equation} z_d=\mu_{\phi,d}(X,Y)+\sigma_{\phi,d}(X,Y)\epsilon_d \end{equation} 観測値が独立同分布に従うと仮定すると、式(\ref{eq11})の中にある対数尤度は以下のように変形される。 \begin{equation} \ln{p(Y|X,\vec{z})}= \sum^{N}_{n=1}\ln{p(\vec{y}_n|\vec{x}_n,\vec{z})} \end{equation} さらに計算を進めるには、具体的に$X,Y$として、何を与えるか決定しなければならない。 ここでは、$X$として0から9までのラベルを、$Y$としてMNISTの画像(2値画像)を与えることにする。$X$の各観測値$\vec{x}_n$は$9$次元のone-hotベクトルで表現される。各画素が独立同分布に従うと仮定すると、$\vec{y}_n$の次元数を$M$として \begin{equation} \ln{p(\vec{y}_n|\vec{x}_n,\vec{z})}=\sum_{m=1}^{M}\ln{p(y_{n,m}|\vec{x}_n,\vec{z})} \end{equation} と書くことができる。いま考える画像は0と1から構成されるから、$p(y_{n,m}|\vec{x}_n,\vec{z})$として0と1を生成するBernoulli分布を仮定する。 \begin{eqnarray} p(y_{n,m}|\vec{x}_n,\vec{z})&=&\mathrm{Bern}\left(y_{n,m}|\eta_{\theta,m}\left(\vec{x}_n,\vec{z}\right)\right) \\ \mathrm{Bern}(x|\eta)&=&\eta^{x}(1-\eta)^{1-x} \end{eqnarray} $\eta_{\theta,m}\left(\vec{x}_n,\vec{z}\right)$は、入力が$\vec{x}_n$と$\vec{z}$、パラメータとして$\theta$を持つニューラルネットワークで学習される。以上を踏まえて処理の流れを書き直すと下図となる。

次に式(\ref{eq10})を考える。これは、観測値$X,Y$とラベル$\vec{x}_{\alpha}$が与えられときの$\vec{y}_{\alpha}$の実現確率である。 \begin{equation} p(\vec{y}_{\alpha}|\vec{x}_{\alpha},X,Y)\approx \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;p(\vec{y}_{\alpha}|\vec{x}_{\alpha},\vec{z}) \end{equation} ここで、$z_d=\mu_{\phi,d}(X)+\sigma_{\phi,d}(X)\epsilon_d$である。上式は以下のように書くことができる。 \begin{equation} \prod_{m=1}^M p(y_{\alpha,m}|\vec{x}_\alpha,X,Y)\approx \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;\prod_{m=1}^M p(y_{\alpha,m}|\vec{x}_\alpha,\vec{z}) \end{equation} すなわち、要素$y_{\alpha,m}$ごとに次式が成り立つ。 \begin{equation} p(y_{\alpha,m}|\vec{x}_\alpha,X,Y)\approx \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;p(y_{\alpha,m}|\vec{x}_\alpha,\vec{z}) \end{equation} $p(y_{\alpha,m}|\vec{x}_\alpha,\vec{z})$としてBernoulli分布を仮定したから \begin{equation} p(y_{\alpha,m}|\vec{x}_\alpha,X,Y)\approx \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;\mathrm{Bern}(y_{\alpha,m}|\eta_{\theta,m}(\vec{x}_\alpha,\vec{z})) \end{equation} となる。確率分布$p(y_{\alpha,m}|\vec{x}_\alpha,X,Y)$の下での$y_{\alpha,m}$の期待値は \begin{eqnarray} <y_{\alpha,m}>&=&\sum_{y_{\alpha,m}=0,1} y_{\alpha,m}\;p(y_{\alpha,m}|\vec{x}_\alpha,X,Y) \\ &\approx& \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;\sum_{y_{\alpha,m}=0,1} y_{\alpha,m} \mathrm{Bern}(y_{\alpha,m}|\eta_{\theta,m}(\vec{x}_\alpha,\vec{z})) \\ &=& \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;\eta_{\theta,m}(\vec{x}_\alpha,\vec{z}) \end{eqnarray} となる。$\vec{z}$は$\vec{\epsilon}$に依存する項であることに注意する。$\eta_{\theta,m}(\vec{x}_\alpha,\vec{z})$はDecoderの出力である。上式から、復号化した結果を得るには、$\eta_{\theta,m}(\vec{x}_\alpha,\vec{z})$を標準正規分布に従ってサンプリングすれば良いことが分かる。さらに、式(\ref{eq8})のKullback Leibler divergenceを十分小さくできれば、すなわち、$\sigma_{\phi,d}(X,Y)\rightarrow 1,\mu_{\phi,d}(X,Y)\rightarrow 0$とできれば、$\vec{z}=\vec{\epsilon}$とすることができるので、標準正規分布から生成した値$\vec{\epsilon}$と$\vec{x}_\alpha$からDecoderの出力を直接得ることができる。
まとめ
今回は、CVAEをBayes推定の枠組みで説明した。前回のVAEの論法とほとんど同じである。VAEでは未観測データ$\vec{x}$が従う確率分布$p(\vec{x}|X)$を求める過程でVAEの構造を見出した。一方、CVAEでは未観測データ$\vec{x}$に対応する$\vec{y}$が従う確率分布$p(\vec{y}|\vec{x},X,Y)$を求める過程でCVAEの構造が現れることを見た。その構造は、VAEに少し手を加えれば実現できる程度のものである。ChainerのVAEのサンプルコードをベースにすればすぐに実装できそうである。
2018年4月22日日曜日
Variational Auto Encoder 〜その2〜
はじめに
先のページで、Variational Auto Encoder(VAE)をBayes推論の枠組みで解説し、Chainerのサンプルコードをみた。今回は、サンプルコードを実際に動かし、その動作を確認する。
前回の補足
前回の式(16)は、観測値$X$の下での未知変数$\vec{x}$の実現確率であった。 \begin{equation} p(\vec{x}|X)\approx \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;p(\vec{x}|\vec{z}) \end{equation} ここで、$z_d=\mu_{\phi,d}(X)+\sigma_{\phi,d}(X)\epsilon_d$である。$\vec{x}$の各成分が独立同分布で生成されると仮定すると、以下のように書き換えることができる。 \begin{equation} \prod_{m=1}^M p(x_{m}|X)\approx \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;\prod_{m=1}^M p(x_m|\vec{z}) \end{equation} すなわち、要素$x_m$ごとに次式が成り立つ。 \begin{equation} p(x_{m}|X)\approx \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;p(x_m|\vec{z}) \end{equation} $p(x_m|\vec{z})$としてBernoulli分布を仮定したから \begin{equation} p(x_{m}|X)\approx \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;\mathrm{Bern}(x_m|\eta_{\theta,m}(\vec{z})) \end{equation} となる。確率分布$p(x_{m}|X)$の下での$x_m$の期待値は \begin{eqnarray} <x_m>&=&\sum_{x_m=0,1} x_m\;p(x_{m}|X) \\ &\approx& \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;\sum_{x_m=0,1} x_m \mathrm{Bern}(x_m|\eta_{\theta,m}(\vec{z})) \\ &=& \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;\eta_{\theta,m}(\vec{z}) \end{eqnarray} となる。$\vec{z}$は$\vec{\epsilon}$に依存する項であることに注意する。ここまでの議論で言えることは、復号化した結果を得るには、$\eta_{\theta,m}(\vec{z})$を標準正規分布に従ってサンプリングすれば良いということである。$\eta_{\theta,m}(\vec{z})$はDecoderの出力である。
Chainerの実装の確認
前回は、net.pyを見たので、今回はtrain_vae.pyを見る。trainerを用いた実装部分は特に指摘することはないので、結果を描画している箇所を解説する。最初は訓練データに関わる描画部分である。 適当に画像を9枚選択し、これを関数__call__で符号化・復号化している。前回指摘したように、復号化の際、$\sigma_{\phi,d}(X)$は無視されている。計算のあと元画像と復号化画像を保存している。epochを100とした結果は以下の通りである。
訓練画像

復号化した訓練画像

次はテスト画像に関わる部分である。 ここでも適当に9枚の画像を選択し、元画像と復号化画像を保存している。epochを100とした結果は以下の通りである。
テスト画像

復号化したテスト画像

最後に、標準正規分布に従う値$\vec{z}$から復号化する部分である。 9個の乱数$\vec{z}$を作り、関数decodeを呼び出している。epochを100とした結果は以下の通りである。

訓練・テスト画像を符号化・復号化した結果と比べるとかなり精度の悪い結果である。関数decodeは$\eta_{\theta,m}(\vec{z})$を出力する。上で見たように本来の$\vec{z}$は、$z_d=\mu_{\phi,d}(X)+\sigma_{\phi,d}(X)\epsilon_d$として与えらるべきものである。精度が悪いのは、$\vec{z}$を標準正規分布に置き換えたことが原因である。ところで、勾配降下法で最小にすべき式の1つが次式であった(前回の式(19))。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]= \frac{1}{2} \sum_{d=1}^{D}\left\{ -\ln{\sigma^2_{\phi,d}(X)}-1+\sigma^2_{\phi,d}(X)+\mu_{\phi,d}^2(X) \right\} \end{equation} これを十分小さくできれば、すなわち、$\sigma_{\phi,d}\rightarrow 1, \mu_{\phi,d}\rightarrow 0$とできれば、標準正規分布による置き換えは意味があるものになる。残念ながらepochを1000としても大して精度は良くならない。Chainerのサンプル実装を変更する必要があるかもしれない。
まとめ
今回は、$<x_m>$が$\eta_{\theta,m}(\vec{z})$を求めることに帰着すること示し、Chainerのサンプルコードの計算結果を考察した。 さらに、標準正規分布による$\vec{z}$から計算した画像の精度が悪い理由についても述べた。改善するには、epoch数を増やすだけではなくコードの見直し(多層化、初期化関数の変更)も必要であろう。次回はこの辺りのことについてまとめたい。
2018年4月15日日曜日
Variational Auto Encoder
はじめに
Variational Auto Encoder(VAE)をBayes推論の枠組みで解説し、Chainerのサンプルコードを読解する。
問題設定
観測値$X=\{\vec{x}_1,\cdots,\vec{x}_N\}$が与えられたとき、未知の値$\vec{x}_*$を生成する確率分布$p(\vec{x}_*|X)$を求めたい。潜在変数$\vec{z}$を導入し、$X$と$\vec{z}$の同時確率分布$p(X,\vec{z})$を考え、Bayesの定理を適用すると次式を得る。 \begin{equation} p(\vec{z}|X) = \frac{p(X|\vec{z})p(\vec{z})}{p(X)} \label{eq9} \end{equation} 事後確率$p(\vec{z}|X)$が求まれば、次式により$\vec{x}_*$を生成する確率分布を求めることができる。 \begin{equation} p(\vec{x}_*|X)=\int d\vec{z}\;p(\vec{x}_*|\vec{z})p(\vec{z}|X) \label{eq3} \end{equation} 事後確率$p(\vec{z}|X)$を求めることが目的である。
最適化すべき量
$p(\vec{z}|X)$を直接求めることはせず、パラメータ$\phi$を持つ関数$q_{\phi}(\vec{z}|X)$を導入し、次のKullback Leibler divergenceを最小にすることを考える。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}|X) \right]=\int d\vec{z}\;q_{\phi}(\vec{z}|X) \ln{ \frac{ q_{\phi}(\vec{z}|X) } { p(\vec{z}|X) } } \end{equation} これを変形すると次式を得る。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}|X) \right] = D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]-E_{q_{\phi}(\vec{z}|X)}\left[\ln{p(X|\vec{z})}\right]+\ln{p(X)} \label{eq1} \end{equation} ただし、式変形の途中で式(\ref{eq9})を用いた。式(\ref{eq1})右辺にある$\ln{p(X)}$は$\phi$に依存せず、観測値だけから決まる定数である。従って、次式が成り立つ。 \begin{equation} \min_{\phi} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}|X) \right] = \min_{\phi} {\left[ D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]-E_{q_{\phi}(\vec{z}|X)}\left[\ln{p(X|\vec{z})}\right] \right] } \label{eq2} \end{equation} 式(\ref{eq2})の右辺第1項を小さく、第2項の期待値を大きくすれば良い。第1項は$q_{\phi}(\vec{z}|X)$をできるだけ$p(\vec{z})$に近い形の分布にすることを要求し、この分布の下で対数尤度$\ln{p(X|\vec{z})}$の期待値を大きくすることを第2項は要求する。第1項は正則化項に相当する。
KL divergenceの計算
式(\ref{eq2})の右辺第1項を考える。いま次の仮定をおく。 \begin{eqnarray} q_{\phi}(\vec{z}|X)&=&\mathcal{N}(\vec{z}|\vec{\mu}_{\phi}(X),\Sigma_{\phi}(X)) \\ p(\vec{z})&=&\mathcal{N}(\vec{z}|\vec{0},I_D) \end{eqnarray} ここで、$\vec{z}$の次元を$D$とした。$I_D$は$D\times D$の単位行列である。どちらの分布も正規分布とし、$q_{\phi}(\vec{z}|X)$の平均と共分散行列は$\phi$と$X$から決まる量とする。これらは、入力$X$、パラメータ$\phi$のニューラルネットワークを用いて計算される。一方、$p(\vec{z})$の方は平均0、分散1の標準正規分布である。このとき、$D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]$は解析的に計算することができる。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]=\frac{1}{2}\left[ -\ln{|\Sigma_{\phi}(X)|} -D +\mathrm{Tr}\left(\Sigma_{\phi}(X)\right)+\vec{\mu}_{\phi}(X)^T\vec{\mu}_{\phi}(X) \right] \label{eq4} \end{equation}
ここまでの処理の流れ
式(\ref{eq2})の最適化を行う際に勾配降下法を用いる。処理の流れは以下のようになる(下図参照)。
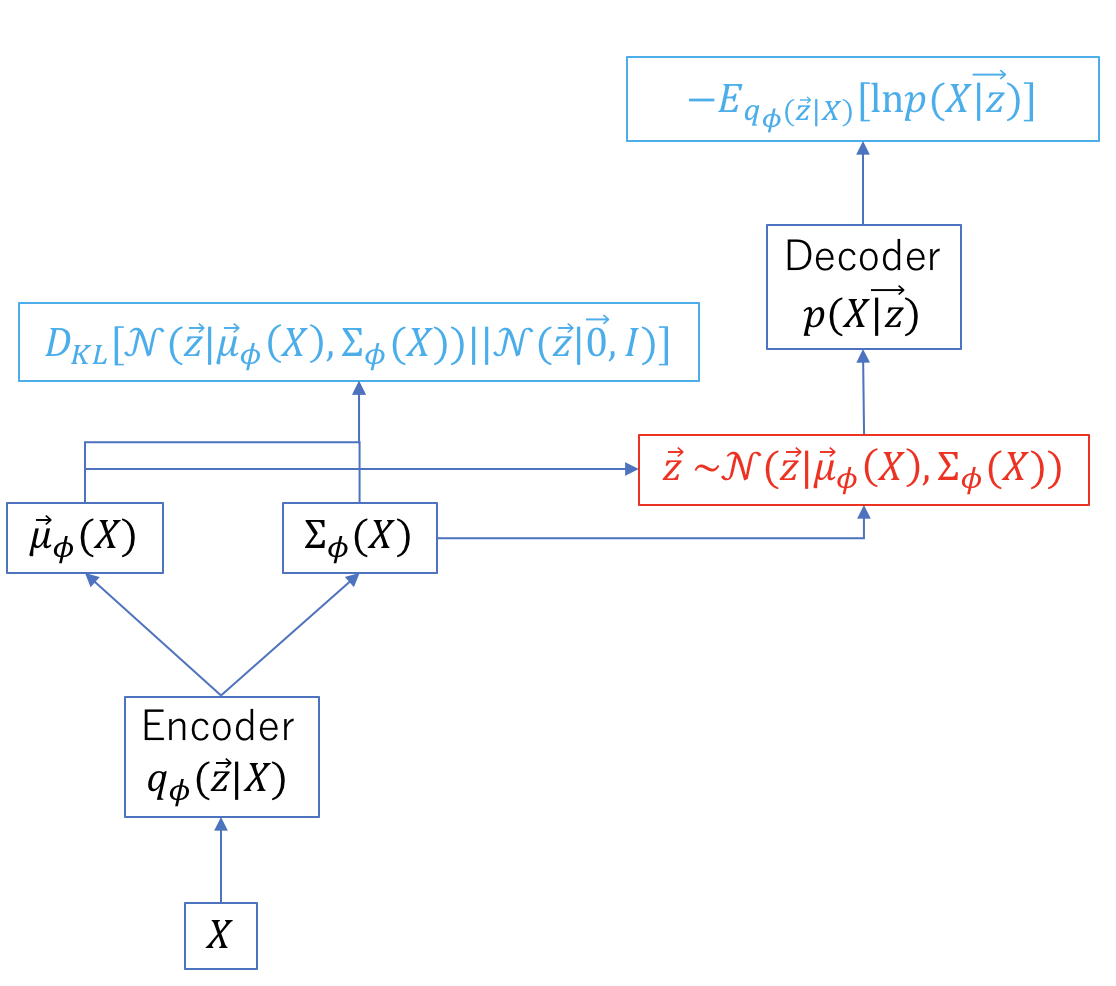
分布$q_{\phi}(\vec{z}|X)$は$X$から$\vec{z}$を生成するEncoder、$p(X|\vec{z})$は$\vec{z}$から$X$を生成するDecoderとみなすことができる。青色で示した部分は最小化すべき量であり、赤字はサンプリングするステップである。勾配降下法を実現するには、誤差逆伝播ができなければならない。$q_{\phi}(\vec{z}|X)$はその$\phi$依存性のため誤差逆伝播時の微分鎖の中に組み込まれるが、サンプリグという処理の勾配を定義することができない。対数尤度の期待値の計算に工夫が必要である。
対数尤度の期待値の計算
計算したい式は次式である。 \begin{equation} E_{q_{\phi}(\vec{z}|X)}\left[\ln{p(X|\vec{z})}\right]=\int d\vec{z}\;q_{\phi}(\vec{z}|X)\ln{p(X|\vec{z})} \end{equation} この式に再パラメータ化トリック(re-parametrization trick)を適用する。すなわち \begin{equation} \vec{z}\sim\mathcal{N}(\vec{z}|\vec{\mu}_{\phi}(X),\Sigma_{\phi}(X)) \end{equation} の代わりに \begin{eqnarray} \vec{\epsilon}&\sim&\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\\ \vec{z}&=& \vec{\mu}_{\phi}(X)+\Sigma_{\phi}^{1/2}(X)\vec{\epsilon} \label{eq7} \end{eqnarray} を用いてサンプリングを行う。これを用いて期待値を書き直すと次式を得る。 \begin{equation} E_{q_{\phi}(\vec{z}|X)}\left[\ln{p(X|\vec{z})}\right]=\int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\ln{p(X| \vec{z}=\vec{\mu}_{\phi}(X)+\Sigma_{\phi}^{1/2}(X)\vec{\epsilon})} \end{equation} このときの処理の流れは以下のようになる(下図参照)。

上図であれば誤差逆伝播が可能となる。
未知変数の生成
未知変数を生成する確率分布は次式で与えられた。 \begin{equation} p(\vec{x}_*|X)=\int d\vec{z}\;p(\vec{x}_*|\vec{z})p(\vec{z}|X) \end{equation} 事後確率$p(\vec{z}|X)$の近似解$q_{\phi}(\vec{z}|X)$を用いると \begin{equation} p(\vec{x}_*|X)\approx\int d\vec{z}q_{\phi}(\vec{z}|X)p(\vec{x}_*|\vec{z}) \end{equation} を得る。先と同様に再パラメータ化トリックを適用すると \begin{equation} p(\vec{x}_*|X)\approx\int d\vec{\epsilon}\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)p(\vec{x}_*| \vec{z}=\vec{\mu}_{\phi}(X)+\Sigma_{\phi}^{1/2}(X)\vec{\epsilon}) \end{equation} となる。
Chainer実装の確認
ChainerのサンプルコードにVAEがある。これはMNISTデータセットにVAEを適用したものである。MNISTは2値画像であるから$\vec{x}_n$として0と1が784(=28$\times$28)個並んだベクトルを考えることになる。実際にコードを見て行く前に先に導出した式をもう少し詳細に計算しておく。
最初に$\vec{\mu}_{\phi}(X)$と$\Sigma_{\phi}(X)$を次のように置く。 \begin{eqnarray} \vec{\mu}_{\phi}(X)&=&(\mu_{\phi,1}(X),\cdots,\mu_{\phi,D}(X))^T \label{eq5}\\ \Sigma_{\phi}(X)&=&\mathrm{diag}(\sigma^2_{\phi,1}(X),\cdots,\sigma^2_{\phi,D}(X)) \label{eq6} \end{eqnarray} このとき式(\ref{eq4})は次式となる。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]= \frac{1}{2} \sum_{d=1}^{D}\left\{ -\ln{\sigma^2_{\phi,d}(X)}-1+\sigma^2_{\phi,d}(X)+\mu_{\phi,d}^2(X) \right\} \label{eq8} \end{equation} また、$\vec{z}$の成分は次式で与えられる。 \begin{equation} z_d=\mu_{\phi,d}(X)+\sigma_{\phi,d}(X)\epsilon_d \end{equation} 観測値が独立同分布に従うと仮定すると対数尤度は以下のように変形される。 \begin{equation} \ln{p(X|\vec{z})}= \sum^{N}_{n=1}\ln{p(\vec{x}_n|\vec{z})} \end{equation} $\vec{x}_n$の次元数を$M$(=784)とすると \begin{equation} \ln{p(\vec{x}_n|\vec{z})}=\sum_{m=1}^{M}\ln{p(x_{n,m}|\vec{z})} \end{equation} となる。いま考える画像は0と1から構成される。従って、$p(x_{n,m}|\vec{z})$として0と1を生成する確率分布であるBernoulli分布を仮定する。 \begin{eqnarray} p(x_{n,m}|\vec{z})&=&\mathrm{Bern}\left(x_{n,m}|\eta_{\theta,m}\left(\vec{z}\right)\right) \\ \mathrm{Bern}(x|\eta)&=&\eta^{x}(1-\eta)^{1-x} \end{eqnarray} $\eta_{\theta,m}\left(\vec{z}\right)$は、入力$\vec{z}$、パラメータ$\theta$のネットワークで学習される量である。 以上を踏まえて処理の流れを書き直すと下図となる。

以上で準備が整ったので順にコードを見ていく。まず最初にネットワークを定義したクラスVAEを見る。コンストラクタは以下の通り。 Encoderとして$\vec{\mu}_{\phi}(X)$と$\Sigma_{\phi}(X)$を生成する層がそれぞれ1層ずつ定義されている。Decoderとして$\vec{\eta}_{\theta}(\vec{z})$を生成する2層が定義されている。次に関数encodeを見る。 $\mu_{\phi,d}$と$\ln{\sigma_{\phi,d}^2}$を生成する処理が記述されている。次は関数decodeである。 $\vec{z}$を受け取り$\vec{\eta}_{\theta}(\vec{z})$を返す処理が記述されている。次は__call__である。 Encoderで計算した平均を入力としてDecoderを呼び出している。分散を無視して復号化している。次はget_loss_funcである。
まとめ
今回は、VAEをBayes推論の枠組みで解説し、Chainerのサンプルコードを見た。ニューラルネットワークで計算されるのは確率分布のパラメータであることを明確に示した。言い換えると他の手法でパラメータを計算できるのであればそれでも構わないということである。計算の仮定で確率分布にいくつかの仮定(ガウス分布やBernoulli分布)をしていることに注意しなければならない。今回Bernoulli分布を使用したのはターゲットとした観測値が0と1から構成される2値画像であるためである。2値でない観測値を対象とするならそれに見合った確率分布を導入する必要がある。次回はChainerのコードを動かして得られる結果を考察したい。
参考文献
登録:
投稿 (Atom)