in English
ソースをダウンロードして解凍する。
以下を実行。
完了。
2013年4月28日日曜日
boost 1.53.0をApple LLVM compiler 4.2でコンパイルする
in English
最初にXcode-4.6.1のCommand Line Toolsをインストールする。そして確認。 boost_1_53_0をダウンロードして解凍。 解凍したディレクトリに入って以下を実行。 Xcodeで動かす時は、Product→Edit Scheme→Arguments→Environment Variablesに変数DYLD_LIBRARY_PATHを追加し、dylibへのパスを設定する。
最初にXcode-4.6.1のCommand Line Toolsをインストールする。そして確認。 boost_1_53_0をダウンロードして解凍。 解凍したディレクトリに入って以下を実行。 Xcodeで動かす時は、Product→Edit Scheme→Arguments→Environment Variablesに変数DYLD_LIBRARY_PATHを追加し、dylibへのパスを設定する。
2013年4月24日水曜日
Image Segmentation By Graph Cut
in Japanese
The first term of eq.($\ref{energy}$) is called the data term. Before minimizing the energy, the probability $p_{m}(v)$ is calculated as follows:
The second term of eq.($\ref{energy}$) is called the smoothing term. In this study, we utilize the differential image to represent it. The differential image is calculated by applying the sobel filter to the corresponding gray image. We derive two kinds of images $e_{x}(u)$ and $e_{y}(u)$. The former is the differential image along the x direction, and the latter is that along the y direction. When $u=(x,y)$ and $v=(x+1,y)$, $e(u)$ is replaced by $e_{x}(u)$. When $u=(x,y)$ and $v=(x,y+1)$, $e(u)$ is replaced by $e_{y}(u)$. Those absolute values are divided by the maximum of them to make them equal to or less than 1. If the pair $(u,v)$ of the neighboring pixels has the same labels ($m=n$), the smoothing term has no effect on the energy. On the other hand, if the pair has the different labels ($m\neq n$), the term increases the energy. In the latter case, the pair that exists in the area with the large differential values gives rise to the small contribution on the energy. When the pair exists in the area with the small differential values, the contribution is large.
Based on the discussion so far, to minimize the data term, we only have to assign the label $m$ to the pixel $v$ according to $\mathop{\arg\,\max}\limits_m\;p_{m}(v)$. On the other hand, the minimization of the smoothing term is accomplished by setting the different labels to the pair in the area with the large differential values and by setting the same labels to the pair in the area with the small differential values. The trade-off of them decides the optimal placement $X$.
 The results are shown below. The images of the left column are the results for the current theory, and the right for the previous GMM theory.
The results are shown below. The images of the left column are the results for the current theory, and the right for the previous GMM theory.
The noise in the GMM's results disappears in the graph cut's ones. This is the effect of the smoothing term.
In the next demo, we roughly specifies three regions, sky, rock, and sea.
 The results are shown below.
The results are shown below.
Also, we can see no noise in the graph cut's results. In two demos, we set $\lambda=\kappa(=100)$.
The execution file name is
The following command displays the input image given by
Introduction
So far, I have considered the image segmentations by the K-means clustering and the Gaussian mixture model(GMM).1,2,3 In this page, I show the image segmentation with the graph cut algorithm.Formulation
We define the following energy function: \begin{equation} E(X)=\lambda\;\sum\limits_{v\;\in\; V}\left\{1-p_{m}(v)\right\}+\kappa\;\sum\limits_{(u,v)\;\in \;C}\left(1-\delta_{m,n}\right)\;\left\{\;1-\;\left|e(u)\right|\;\right\} \label{energy} \end{equation} where $v$ is a pixel on an image and $V$ is a set of pixels. It should be noted that $v$ has a position $(x,y)$ and a color $(r,g,b)$. $m$ is a label assigned to each pixel $v \in V$, $C$ indicates a set of pairs of neighboring pixels, $p_{m}(v)$ represents a probability that the pixel $v$ has the label $m$, and $e(v)$ is a differential image. $\lambda$ and $\kappa$ are positive constants, and $\delta_{i,j}$ is the Kronecker delta. $X$ denotes all combinations of $v$ and $m$. The energy $E$ is minimized via the graph cut algorithm to obtain a good segmentation.The first term of eq.($\ref{energy}$) is called the data term. Before minimizing the energy, the probability $p_{m}(v)$ is calculated as follows:
- A user roughly specifies $M$ regions by moving mouse on the given image.
- We get $M$ regions $\{s_{1},\cdots,s_{M}\}$. Each region $s_{m}$ is a set of pixels.
- Applying the EM algorithm for each region $s_{m}$, we calculate the probability $p_{m}(v)$. Here the RGB values are used.
- We regard $m \in \{1,\cdots,M\}$ as the label assigned to each pixel $v$
The second term of eq.($\ref{energy}$) is called the smoothing term. In this study, we utilize the differential image to represent it. The differential image is calculated by applying the sobel filter to the corresponding gray image. We derive two kinds of images $e_{x}(u)$ and $e_{y}(u)$. The former is the differential image along the x direction, and the latter is that along the y direction. When $u=(x,y)$ and $v=(x+1,y)$, $e(u)$ is replaced by $e_{x}(u)$. When $u=(x,y)$ and $v=(x,y+1)$, $e(u)$ is replaced by $e_{y}(u)$. Those absolute values are divided by the maximum of them to make them equal to or less than 1. If the pair $(u,v)$ of the neighboring pixels has the same labels ($m=n$), the smoothing term has no effect on the energy. On the other hand, if the pair has the different labels ($m\neq n$), the term increases the energy. In the latter case, the pair that exists in the area with the large differential values gives rise to the small contribution on the energy. When the pair exists in the area with the small differential values, the contribution is large.
Based on the discussion so far, to minimize the data term, we only have to assign the label $m$ to the pixel $v$ according to $\mathop{\arg\,\max}\limits_m\;p_{m}(v)$. On the other hand, the minimization of the smoothing term is accomplished by setting the different labels to the pair in the area with the large differential values and by setting the same labels to the pair in the area with the small differential values. The trade-off of them decides the optimal placement $X$.
Demos
First we roughly specifies two regions, the background and the bird.
 |

|

|

|
| GraphCut | GMM |
|---|
In the next demo, we roughly specifies three regions, sky, rock, and sea.
 |
 |
 |
 |
 |
 |
| GraphCut | GMM |
|---|
Development Environment
- Mac OS X 10.8.3
- Processor : 3.06 GHz Intel Core 2 Duo
- Memory : 4GB
- Xcode4.6.1 with Apple LLVM 4.2(C++ Language Dialect → GNU++11, C++ Standard Library → libc++)
- boost-1.51.0 built by the Apple LLVM 4.1. See see here
- opencv-2.4.3 built by the Apple LLVM 4.2. See see here.
My Source Code
Here is my source code. I tested it on the above environment.External Library
I used the library GCO Version3 which is the implementation of the graph cut algorithm in C++.
Usage
The execution file name is ImageSegmentationWithGraphCut. Running it without any arguments, it prints the following usage statements on the standard output:
To the option --ratio, we set $r=\kappa/\lambda$. Therefore, $\kappa=r\lambda$, where $\lambda$ is fixed to 100 in code. The meanings of the other arguments are the same as ones in the previous page.
The following command displays the input image given by
--input.
The way we specify regions is the same as one in the previous page. The number of regions, however, that we can specify is 6 from 0 to 5.
Pressing "e" begins the image segmentation, pressing "c" clears all specified regions, and "q" finishes program.
References
2013年4月21日日曜日
GraphCutによる領域分割
in English
式($\ref{energy}$)の右辺第1項はデータ項と呼ばれる。$p_{m}(v)$ は $E$ の最小化に先立って以下のように計算しておく。
「あらかじめ与えられた確率分布に従って画素 $v$ にラベル $m$ を割り振る。最も確度の高いラベルを割り振ったとき、エネルギー $E$ への寄与は最小になる」
第2項は平滑化項と呼ばれる。今回の計算ではエッジ画像を使用した。この量についても、グレー画像にSobelフィルタを適用し、あらかじめ計算しておく。x軸方向、y軸方向の2つのエッジ画像 $e_{x}(u),e_{y}(u)$ を用意し、 $u=(x,y),v=(x+1,y)$ のときは $e_{x}(u)$ を、$u=(x,y),v=(x,y+1)$ のときは $e_{y}(u)$ を選択する。 絶対値が1以下となるように最大値で規格化しておく。平滑化項の物理的意味は以下の通りである。
「隣接画素 $(u,v)$ に割り振るラベル $(m,n)$ の値が同じとき、平滑化項は $E$ に寄与しない。それらが異なる場合、$E$ を増大させる。エッジの値が大きい画素近傍では $E$ への寄与は小さいが、エッジの値が小さい画素近傍での寄与は大きくなる」
ここまでの議論を踏まえると、$E$ の第1項を最小するには確率の大きいラベルを各画素に割り振れば良い。一方、第2項を最小にするには、エッジの大きい画素近傍でラベル値を変え、エッジの小さい画素近傍ではラベル値を同じにすれば良い。これらのトレードオフにより $E$ を最小にする配置$X$が決まる。
実行すると以下のようになる。左が今回の結果、右は前回実装したGMMによる領域分割の結果である。
GMMの結果に見られる細かいノイズが、GraphCutの方ではほとんど消滅していることが分る。これが平滑化項の効果である。
次の結果は3つの領域に分割した場合である。先と同じく大まかに、空、岩、海の領域を指定する。
実行すると以下のようになる。
ここでもGMMに見られるノイズがGraphCutではほとんど見られない。これら2つの計算では$\lambda=\kappa(=100)$とした。
実行ファイ名は、
以下を実行すると、
はじめに
これまで、K-means ClusteringとGaussian Mixture Model(GMM)を利用した領域分割について考えてきた1,2,3 。今回はGMMとGraphCutアルゴリズムを組み合わせて領域分割を行う。定式化
画像上に存在する画素の位置座標の集合を $V$、各画素 $v \in V$ に割り振るラベルを $m$ 、隣接画素の集合を $C$、画素 $v$ にラベル $m$ を割り振る確率を $p_{m}(v)$ 、与えられた画像のエッジ画像を $e(v)$ と書くことにする。 このとき、GraphCutアルゴリズムで最小化すべきエネルギー関数を次式で定義した。 \begin{equation} E(X)=\lambda\;\sum\limits_{v\;\in\; V}\left\{1-p_{m}(v)\right\}+\kappa\;\sum\limits_{(u,v)\;\in\; C}\left(1-\delta_{m,n}\right)\;\left\{\;1-\;\left|e(u)\right|\;\right\} \label{energy} \end{equation} ここで、$\lambda,\kappa$ は正の定数、$\delta_{i,j}$ はクロネッカーのデルタ、$X$ は各画素へのラベルの割り振りかたの全てを表現する変数である。これは「配置」と呼ばれる。GraphCutアルゴリズムを使い、$E$ を最小にするような配置 $X$ を見つけることが目的である。式($\ref{energy}$)の右辺第1項はデータ項と呼ばれる。$p_{m}(v)$ は $E$ の最小化に先立って以下のように計算しておく。
- ユーザがマウスで大まかに $M$ 個の領域を指定する。
- $M$ 個の領域 $\{s_{1},\cdots,s_{M}\}$ が得られる。各領域 $s_{m}$ は画素の集合である。
- 各領域 $s_{m}$ にEMアルゴリズムを適用し、確率分布 $p_{m}(v)$ を算出する。この際、画素のRGB値を使用する。
- $m \in \{1,\cdots,M\}$ を各画素 $v$ に割り振るラベルとみなす。
「あらかじめ与えられた確率分布に従って画素 $v$ にラベル $m$ を割り振る。最も確度の高いラベルを割り振ったとき、エネルギー $E$ への寄与は最小になる」
第2項は平滑化項と呼ばれる。今回の計算ではエッジ画像を使用した。この量についても、グレー画像にSobelフィルタを適用し、あらかじめ計算しておく。x軸方向、y軸方向の2つのエッジ画像 $e_{x}(u),e_{y}(u)$ を用意し、 $u=(x,y),v=(x+1,y)$ のときは $e_{x}(u)$ を、$u=(x,y),v=(x,y+1)$ のときは $e_{y}(u)$ を選択する。 絶対値が1以下となるように最大値で規格化しておく。平滑化項の物理的意味は以下の通りである。
「隣接画素 $(u,v)$ に割り振るラベル $(m,n)$ の値が同じとき、平滑化項は $E$ に寄与しない。それらが異なる場合、$E$ を増大させる。エッジの値が大きい画素近傍では $E$ への寄与は小さいが、エッジの値が小さい画素近傍での寄与は大きくなる」
ここまでの議論を踏まえると、$E$ の第1項を最小するには確率の大きいラベルを各画素に割り振れば良い。一方、第2項を最小にするには、エッジの大きい画素近傍でラベル値を変え、エッジの小さい画素近傍ではラベル値を同じにすれば良い。これらのトレードオフにより $E$ を最小にする配置$X$が決まる。
結果
最初に大まかなに領域を指定する。ここでは背景と鳥の2つを指定している。 |
|
|
|
|
| GraphCut | GMM |
|---|
次の結果は3つの領域に分割した場合である。先と同じく大まかに、空、岩、海の領域を指定する。
|
|
|
|
|
|
|
| GraphCut | GMM |
|---|
開発環境
- Mac OS X 10.8.3
- プロセッサ:3.06 GHz Intel Core 2 Duo
- メモリ:4GB
- Xcode4.6.1 with Apple LLVM 4.2(C++ Language Dialect → GNU++11, C++ Standard Library → libc++)
- boost-1.51.0(Apple LLVM 4.1でコンパイルしたもの。こちら)
- opencv-2.4.3(Apple LLVM 4.2でコンパイルしたもの。こちら)
ソース
ソースは ここからダウンロードできる。上記の開発環境で動作確認した。ライブラリ
GraphCutアルゴリズムのライブラリとしてGCO Version3を利用した。
実行方法
実行ファイ名は、ImageSegmentationWithGraphCutである。引数なしで実行すると以下を出力する。
オプション--ratioに対しては、$r=\kappa/\lambda$の値を指定する。すなわち、$\kappa=r\lambda$となる。$\lambda$の値は100に固定してある。それ以外の引数の意味はここと同じである。
以下を実行すると、
--inputで指定した画像が開く。
マウスによる領域の指定方法はここと同じであるが、指定できる領域の数は0から5までの6つである。"e"を押して実行、"c"で領域の全削除、"q"で終了となる。
参考文献
2013年4月7日日曜日
User Interactive Image Segmentation By Gaussian Mixture Model
in Japanese
 , where each sample
, where each sample
 has
has
 3D vectors as (R,G,B).
We can construct the GMM from
as
3D vectors as (R,G,B).
We can construct the GMM from
as
=\sum\limits_{k=1}^{K}\;\pi_{k}\;\cal N(\vec{x}|\vec{\mu}_{k},\;\bf{\Sigma}_{k}))
, where) represents the probability that a given pixel (
represents the probability that a given pixel ( )
belongs to the segment
)
belongs to the segment
 .
We find the maximum probability among the M probabilities
.
We find the maximum probability among the M probabilities
,\cdots,p_{M}(\vec{x})\}) for the pixel, and assign it into the corresponding region.
for the pixel, and assign it into the corresponding region.

The results are as follows:
background
 ray
ray


The results are as follows:
trees
 leaves
leaves
 cats
cats

 The results are as follows:
The results are as follows:
background
 bird
bird

The execution file name is  in the formulation described on the top of the page.
in the formulation described on the top of the page.
The following command displays the input image. Holding down either of the 0-9 keys, you move the mouse on the image with pressing the left button on the mouse. The numbers from 0 to 9 identify the samples. For example, we can specify the background area with holding down 0 key and the bird area with holding down 1 key. The maximum number of the samples we can spedify is 10.
Pressing "e" begins the image segmentation. If we define two regions, two GMMs are calculated. On the standard output, the means are displayed. As we set
are displayed. As we set
Pressing "c" clears all samples. You can make another sampling.
Introduction
In the previous page, I showed the simple image segmentation by the Gaussian Mixture Model (GMM). I made use of the implementation of the EM Algorithm that the OpenCV library provides to us. In this page, I will make the image segmentation user-interactive, i.e.,- A user roughly specifies some segments into which he/she expects to separate an image by mouse moving.
- From the pixels in each specified segment, the program calculates the GMM that indicates the probability that a pixel belongs to the segment.
- The program applies all GMMs to the entire image to separate it into user specified segments.
Formulation
Suppose that we roughly specify M regions on an image. Thus, we get M samples, where
Demo 1
Firstly we roughly tell the program two segments, the ray and the background regions.
The results are as follows:
background


Demo 2
We roughly tell the program three regions, trees, cats(?), and leaves.
The results are as follows:
trees
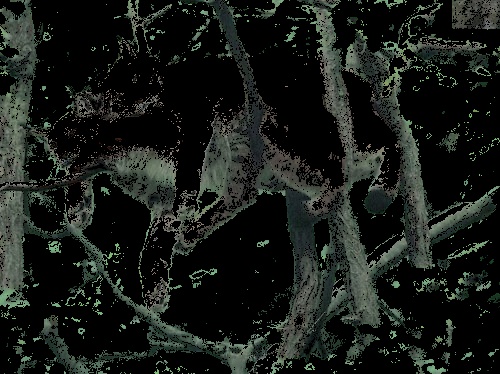


Demo 3
We roughly tell the program two regions, the bird and the background.
background


Development Environment
- Mac OS X 10.8.3
- Processor:3.06 GHz Intel Core 2 Duo
- Memory:4GB
- Xcode4.6.1 with Apple LLVM 4.2(C++ Language Dialect → C++11, C++ Standard Library → libc++)
- boost-1.51.0 built by the Apple LLVM 4.1. See here
- opencv-2.4.3 built by the Apple LLVM 4.2. See here.
My Source Code
Here is my source code. I tested it on the above environment.
Usage
The execution file name is InteractiveImageSegmentation. Running it without any arguments, it prints the following usage statements on the standard output:
The argument --nclusters indicates the number of the components that constitute the Gaussian Mixture Model. It corresponds to the variable
The following command displays the input image. Holding down either of the 0-9 keys, you move the mouse on the image with pressing the left button on the mouse. The numbers from 0 to 9 identify the samples. For example, we can specify the background area with holding down 0 key and the bird area with holding down 1 key. The maximum number of the samples we can spedify is 10.
Pressing "e" begins the image segmentation. If we define two regions, two GMMs are calculated. On the standard output, the means
--nclusters to 5, five 3D vectors for each GMM are printed.Pressing "c" clears all samples. You can make another sampling.
C++ メモ
メモリリーク
以下のように書くとメモリリークするかもしれない。 関数の引数を評価する順序は不定なので、- new int(5)
- seed()
- std::shared_ptr
のコンストラクタ呼び出し
std::begin/end
std::begin/endを使えば統一的に記述できる。lambda trick
参照サイト 9行目の()でlambda式が実行される。
mutable lambda
mutableの記述がないと6行目はコンパイルエラーになる。mutableのあるlambda式は非constメンバ関数、mutableのないlambda式はconstメンバ関数である。
2013年4月6日土曜日
ユーザインタラクティブな領域分割
in English
が得られる。ここで、各サンプル
は
個の(R,G,B)を持つとする。
からGMM
を構築する。ここで、は、与えられた画素値()
が領域
に属する確率を表す。M個の確率分布
を求め、最大確率を与える領域にその画素を割り振る。
実行するとこうなります。
背景
エイ
実行するとこうなります。
木
葉
豹
実行するとこうなります。
背景
鳥
実行ファイ名は、
に相当します。
以下を実行すると
が表示されます。
はじめに
先のページで、OpenCVを使って、GMM(Gaussian Mixture Model)による領域分割を実装しました。今回はこれをユーザインタラクティブな形式に拡張してみます。すなわち、- 分割したい領域をマウスでおおまかに指定する。
- 指定された画素から、各領域のGMMを構築する。GMMは画素がその領域に属する確率分布を与える。
- 各GMMを全画素に適用し、領域分割を行う。
定式化
いま、ユーザがM個の領域をマウスでおおまかに指定したとする。このとき、M個のサンプル群を構築する。ここで、
デモ 1
エイと背景をおおまかに指定する。実行するとこうなります。
背景
デモ 2
木、豹(?)、葉をおおまかに指定する。実行するとこうなります。
木
デモ 3
背景と鳥をおおまかに指定する。背景
開発環境
- Mac OS X 10.8.3
- プロセッサ:3.06 GHz Intel Core 2 Duo
- メモリ:4GB
- Xcode4.6.1 with Apple LLVM 4.2(C++ Language Dialect → C++11, C++ Standard Library → libc++)
- boost-1.51.0(Apple LLVM 4.1でコンパイルしたもの。こちら)
- opencv-2.4.3(Apple LLVM 4.2でコンパイルしたもの。こちら)
ソース
こちらです。上記の開発環境で動作確認しました。
実行方法
実行ファイ名は、InteractiveImageSegmentationです。引数なしで実行すると以下を出力します。
引数--nclustersはGaussian Mixture Modelで使う成分の数です。上記の定式化の
以下を実行すると
--inputで指定した画像が表示されます。
0から9までのいずれかのキーを押しながら、画像上でマウスを左クリックのまま動かします。0から9までの数でサンプルを区別します。たとえば、0を押しながら背景を指定し、1を押しながら鳥を指定します。最大10個のサンプル(ピクセルの集合)を指定することができます。続いて"e"を押すと領域分割が実行されます。
2つのサンプルを指定したので、2つのGMMが計算されました。標準出力にはそれぞれの
--nclusters 5としたので各GMMに対して5つの3次元ベクトルが出力されています。
"c"を押すと全サンプルが削除されます。もう一度最初からサンプルの採集を行うことができます。
登録:
投稿 (Atom)