1. はじめに
論文「Learning Convolutional Neural Networks for Graphs」のアルゴリズムについてまとめる。
2. 本論文の目的
本論文の目的は、一般的なグラフにConvolutional Neural Network(CNN)を適用することである。CNNでは畳み込み処理を行うが、これをグラフに適用する手順が提案されている。本論文で考案されたグラフ構造のためのCNNを著者らはPatchy-sanと名付けている。
3. CNNとグラフ
最初に、画像に適用されるCNNを考えてみる。図1は畳み込みに使うフィルタ(Receptive Field: 以下RF)、図2はRFを画像(4$\times$4)に適用している様子を表したものである(本論文より引用)。
 |
| 図1 |
 |
| 図2 |
画像の形状は矩形であり、RFも矩形とするのが一般的である。さらに、RFを適用していく順番は左上から右下である。ところで、画像は形状が矩形であるグラフとみなすことができる。このときのノードは画素である。本論文は、任意の形状を持つグラフに適用できるように上記の手順を一般化する方法を提案している。一般化するには2つの手順を明確にする必要がある。
- RFを適用するノードとその順番(ノード・シーケンス)を決める。
- RFの形状を決める。
この2つを決めれば、通常のCNNのアルゴリズムに載せる事ができる。
4. ノード・シーケンスの決定
画像の場合、画素の並びは左上から右下に向かって「ラベル」が付けられていると考え、ノード・シーケンスもそれに従い決定される。一般のグラフに対し一番最初に行うことは、各ノードに「ラベル」を付ける事である。ただし、以下の条件を満たすラベルでなければならない。
任意の2つのグラフ$G$と$G^{\prime}$を考える。$G$を構成するあるノード$n_G$の局所的な接続関係が、$G^{\prime}$内のあるノード$n_{G^{\prime}}$の局所的な接続関係と似ているなら、これら2つのノードに割り当てるラベルも似ている。
本論文ではこれを満たす2つの方法を取り上げている。
- 1次元Weisfeiler-Lehmanアルゴリズムを用いたラベリング
- Centralityを用いたラベリング
次にこれらを説明する。
4-1. 1次元Weisfeiler-Lehman(WL)アルゴリズムを用いたラベリング
アルゴリズムの手順は以下の通りである。
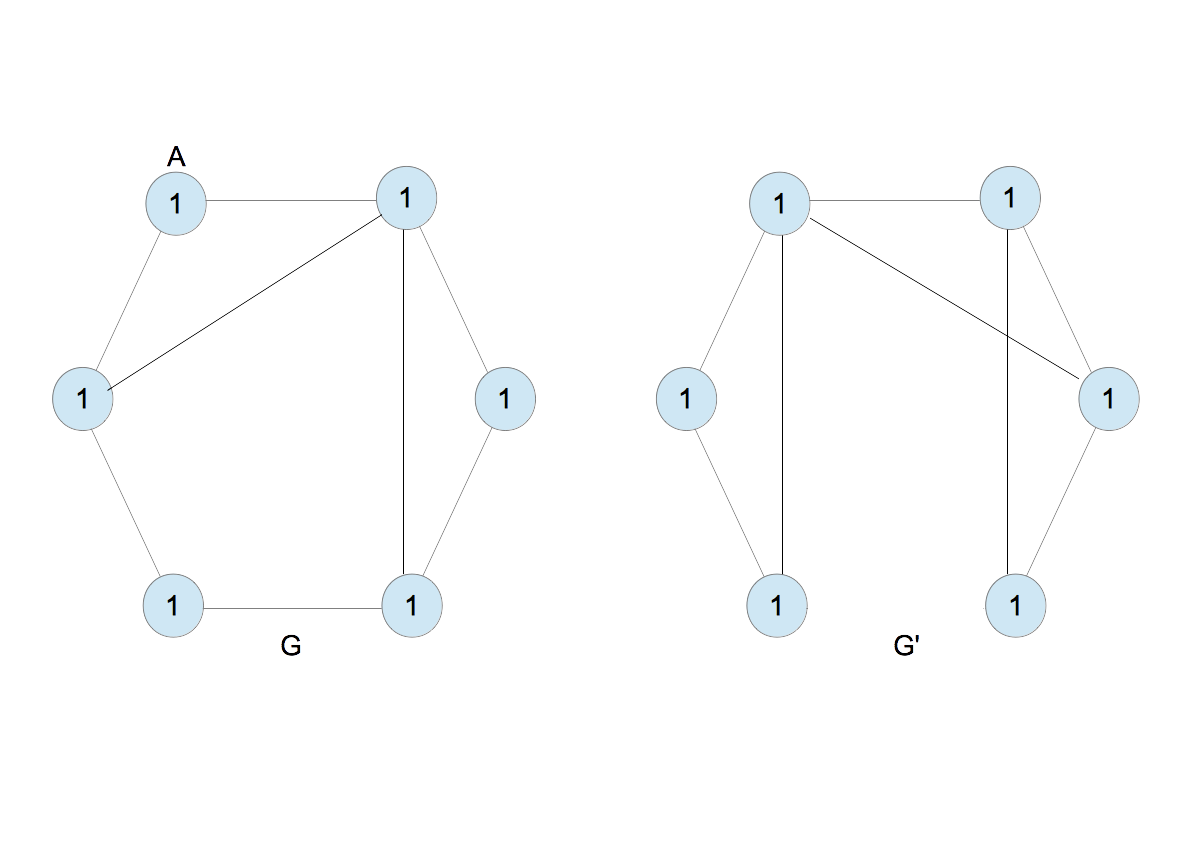
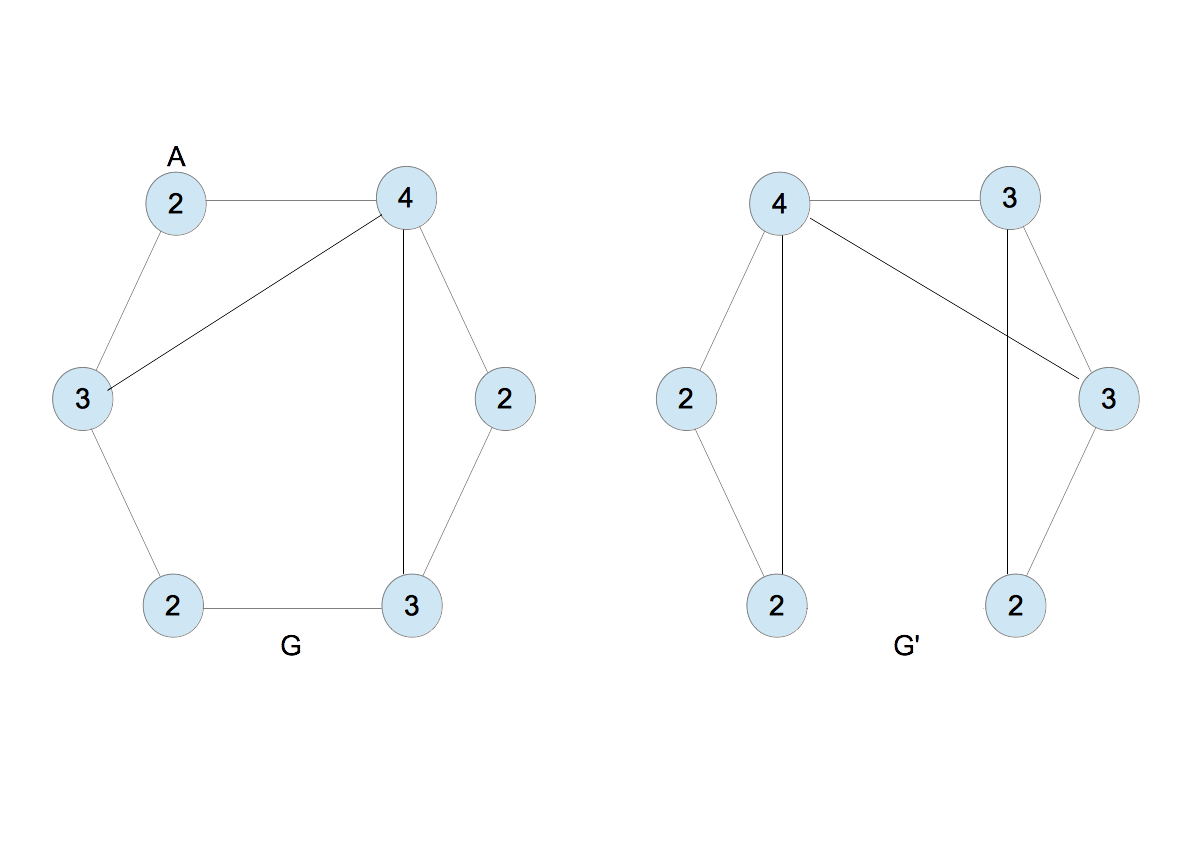
- 2つのグラフ$G$と$G^{\prime}$を考える。最初に各ノードに1を割り振る(図3)。
 |
| 図3 |
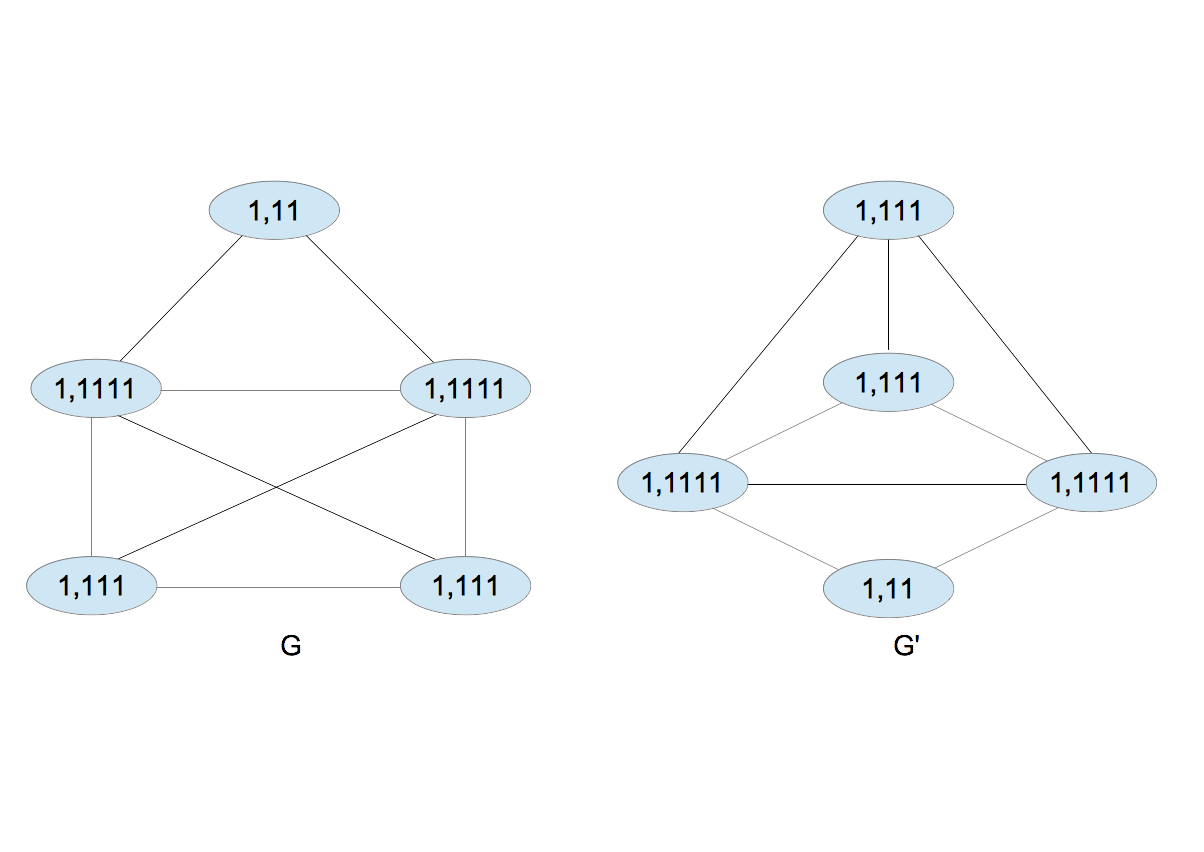
- ノードAを考える(図3)。Aは右と左のノードと接続しており、そのラベルはいずれも1である。この関係を1,11と書くことにする。カンマの前にAのラベルを、カンマの後ろに右と左のラベルを並べて書いたものである。カンマの後ろに並ぶ数字の順序はあとでソートするので任意でよい。同じ事を全てのノードについて繰り返すと図4を得る。
 |
| 図4 |
- 1,11などを文字列とみて昇順に並べ、新たなラベルを割り当てる。新たなラベルは既存のラベルを上書きしないものとする。
1,11 $\rightarrow$ 2
1,111 $\rightarrow$ 3
1,1111 $\rightarrow$ 4
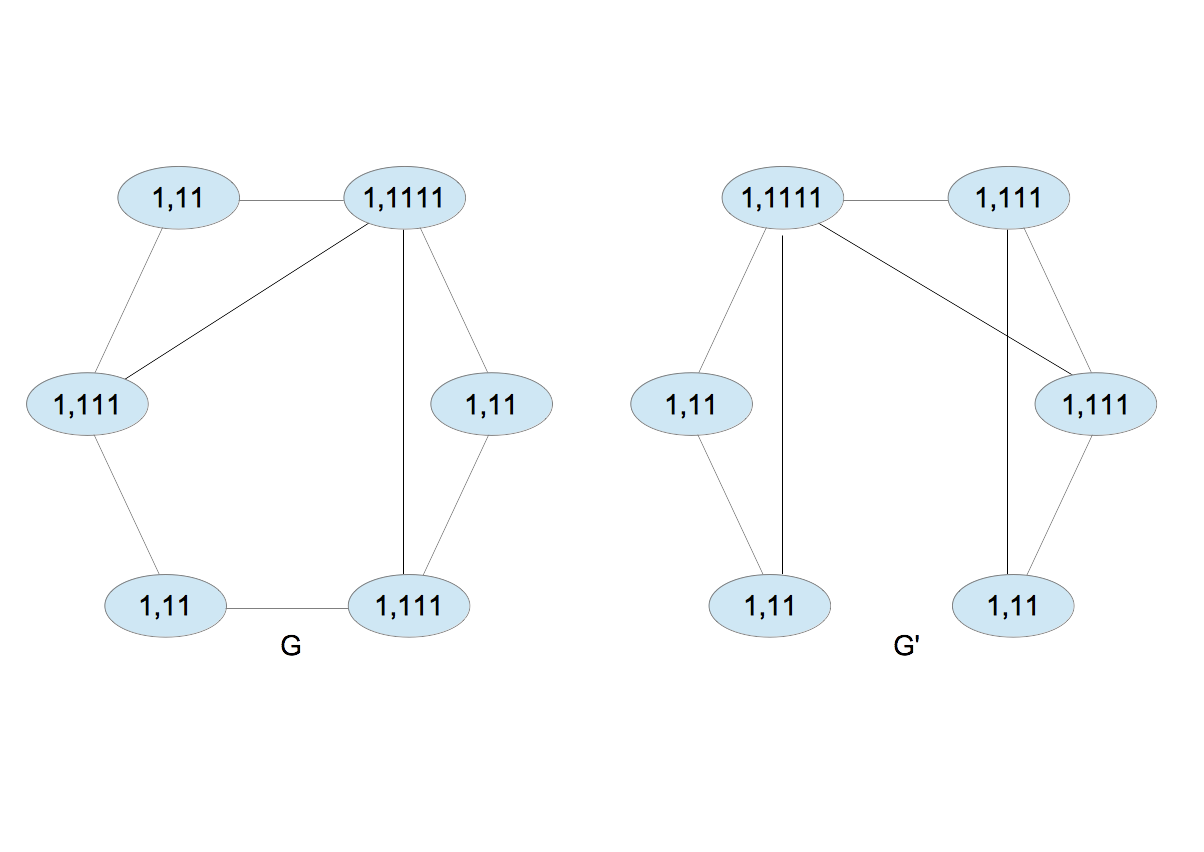
- $G$と$G^{\prime}$の各ノードに新たなラベルを付ける(図5)。$G$のラベルは$\{2,2,2,3,3,4\}$、$G^{\prime}$のラベルは$\{2,2,2,3,3,4\}$であり、これらは同じである。同じ場合、2と3の手順を繰り返す。
 |
| 図5 |
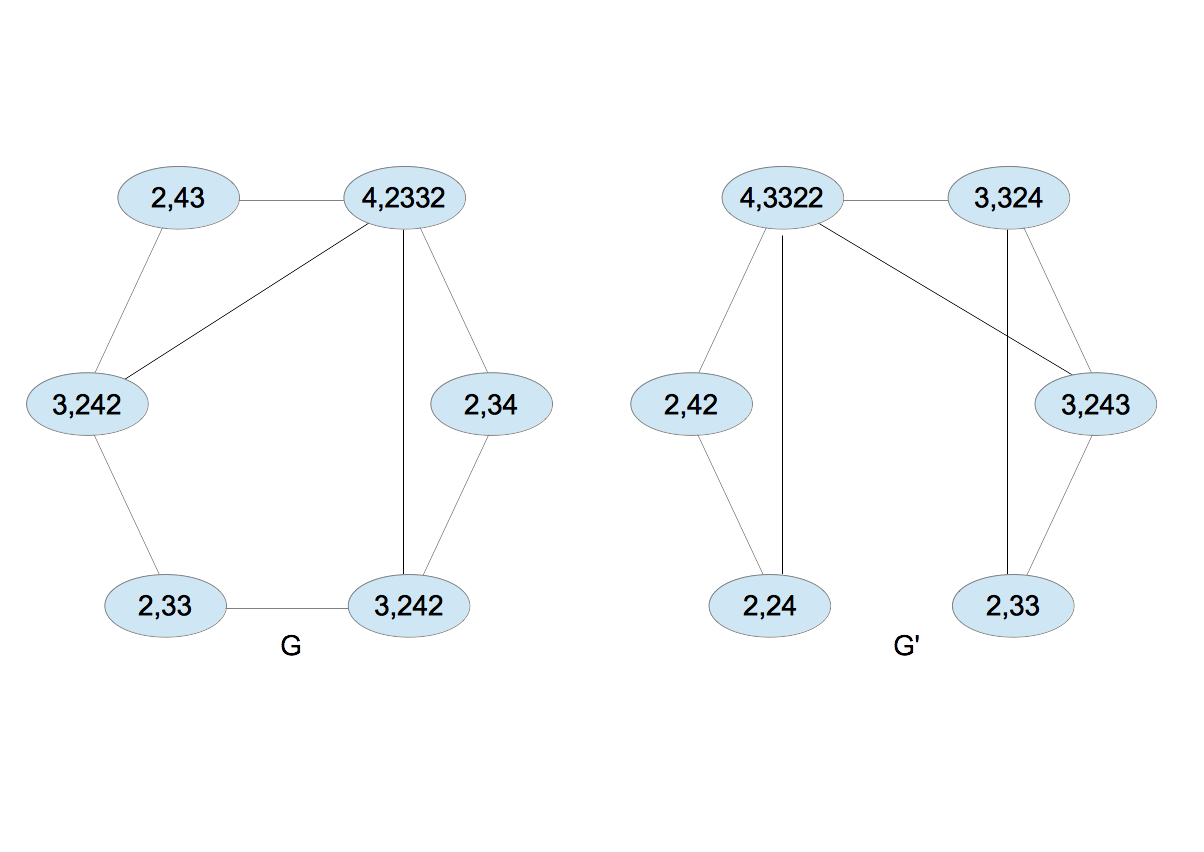
- ノードAを考える。先と同じように接続関係から2,43を得る。今度はラベルが同じとは限らないことに注意する。同じことを全てのノードについて繰り返すと図6を得る。
 |
| 図6 |
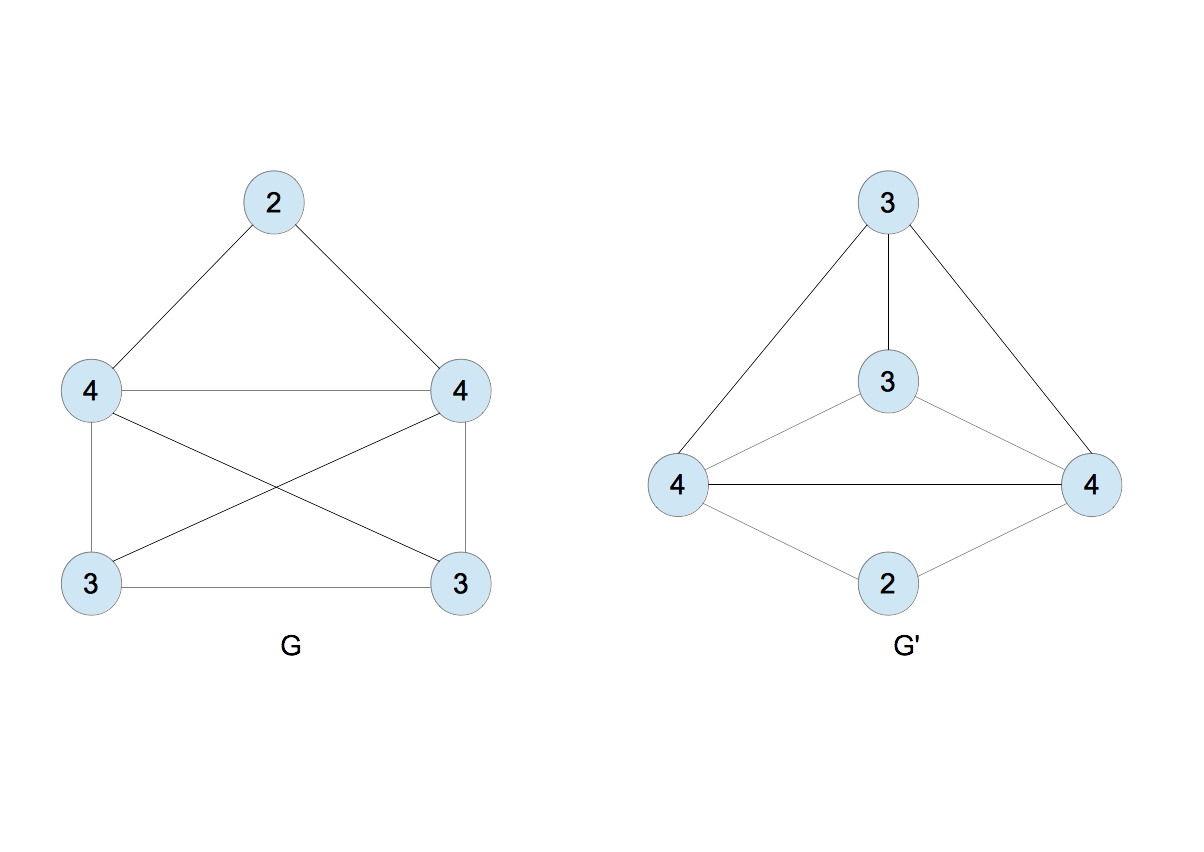
- カンマの後ろに並ぶ数字を昇順に並べ替える。例えば、2,43を2,34とする。同じことを他のラベルについても繰り返す。得られたラベルを文字列とみなしてソートし、新たなラベルを割り当てる。
2,24 $\rightarrow$ 5
2,33 $\rightarrow$ 6
2,34 $\rightarrow$ 7
3,224 $\rightarrow$ 8
3,234 $\rightarrow$ 9
4,2233 $\rightarrow$ 10
- 新たなラベルを$G$と$G^{\prime}$に割り当てる(図7)。
 |
| 図7 |
- 図7のとき、$G$のラベルは$\{6,7,7,8,8,10\}$、$G^{\prime}$のそれは$\{5,5,6,9,9,10\}$となり、これらは異なる。異なるとき終了する。ただし、何回繰り返しても終了しない場合があり得るので、あらかじめ適当な繰り返し数の上限を決めておく。
- 異なるグラフに属する2つのノードが類似の接続関係を持つなら、これらのノードは類似のラベル値を持つ。また、ラベル値が大きいノードは、多くの隣接ノードと連結していることになる。
- あらかじめ決めておいた回数だけ繰り返した結果、ラベルのセットが同じになるなら、「これらのグラフは同型である」か、「同型でないと結論づけることはできない」かのいずれかである。ほとんどの場合、同型であると結論してよい。
- 上で取り上げた2つのグラフのノードの総数は12である。このときラベルの上限値は12としてよい。従って、繰り返し数の上限値は、いま現在使われているラベルの最大値から判断することができる。
上で取り上げた2つのグラフは同型でない場合であった。念のため、同型となる場合の例を以下に示す。
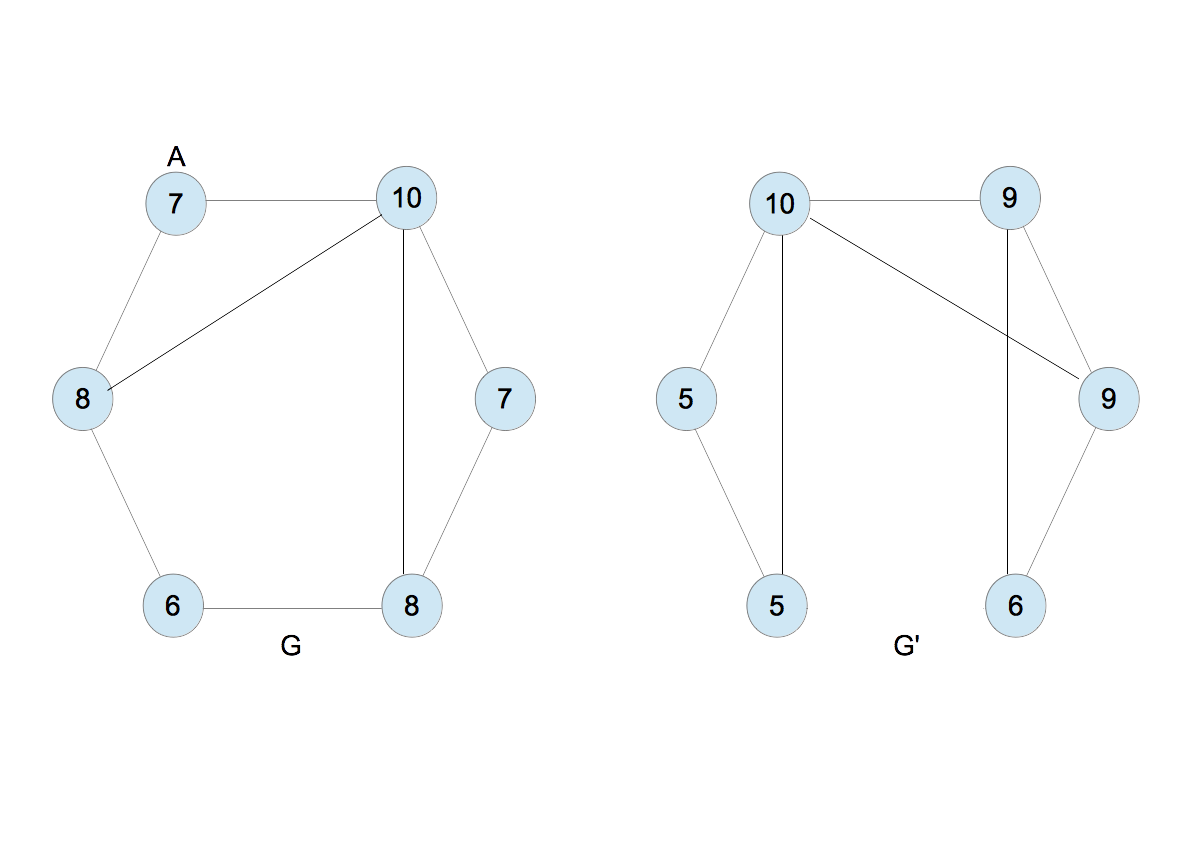
- $G$と$G^{\prime}$の各ノードに1を割り振る(図8)。
 |
| 図8 |
- 先と同じ手順を行うと図9を得る。
 |
| 図9 |
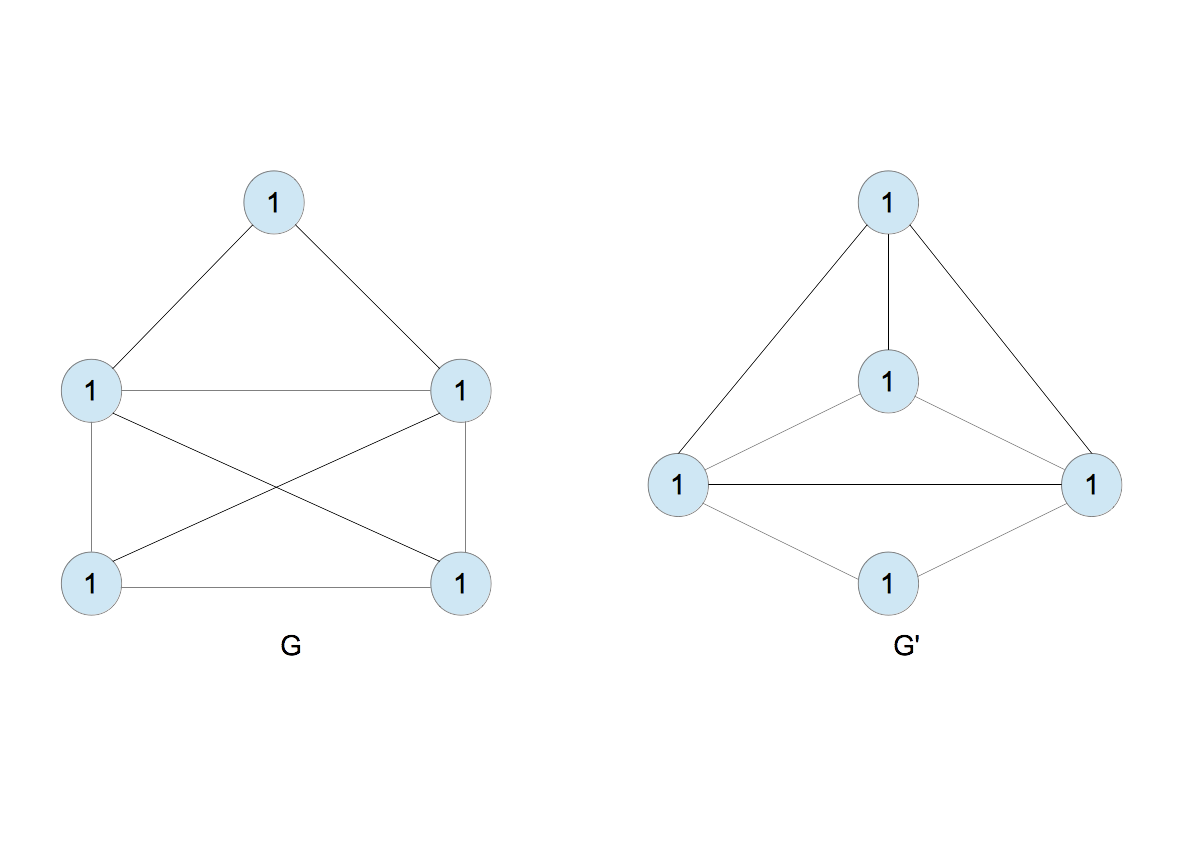
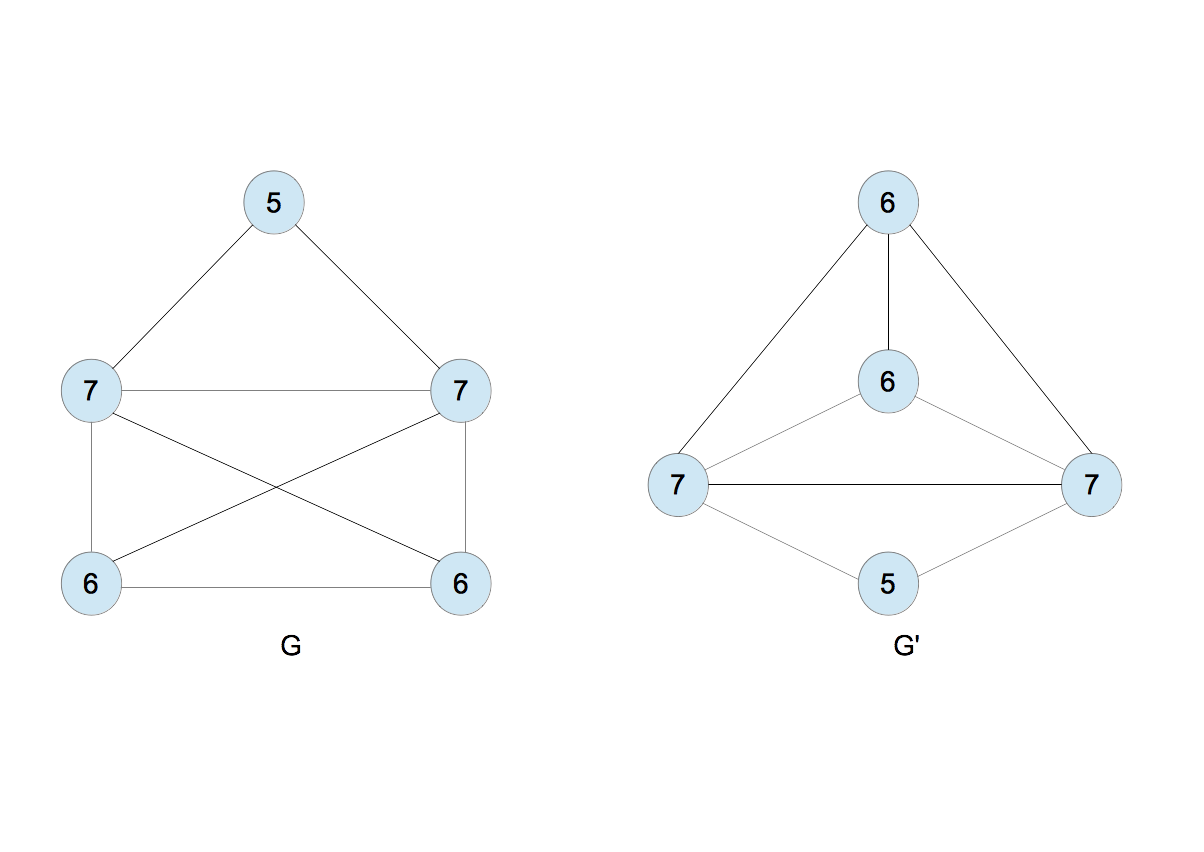
- 1,11 < 1,111< 1,1111と並べ、2,3,4を割り当てる(図10)。
 |
| 図10 |
- $G$のラベルは$\{2,3,3,4,4\}$、$G^{\prime}$のそれは$\{2,3,3,4,4\}$であり同じなので、手順を繰り返す(図11)。2,44 < 3,344 < 4,2334と並べ替え、新たなラベル5,6,7を割り当てる(図12)。
 |
| 図11 |
 |
| 図12 |
- $G$と$G^{\prime}$のラベルは同じになる。いまの場合、何回繰り返しても同じままである。
- 2つのグラフは同型である。
ここまでは、2つのグラフを取り上げてラベリングの手順を見てきた。Patchy-sanに本アルゴリズムを適用する際は、訓練データとなる全てのグラフを対象としなければならない。
4-2. Centralityによるラベリング
Centralityとは、グラフ内における各ノードの重要性を表す指標である。Centralityが大きいノードほど「重要」となる。Centralityにはいくつかの種類があり、その代表的なものは以下のものである。
- Betweenness Centrality
- 任意に取り出した2つのノードを結ぶ最短経路を見つける。
- その経路上にある各ノードに+1を与える。
- この手順を繰り返す。
- 大きな値を持つノードは、最短経路に寄与する回数が多く、重要なノードである。
- Closeness Centrality
- あるノードを考え、このノードから他の任意の複数のノードへの最短経路を見つける。
- 最短経路の長さの平均値をそのノードのCentralityとする。
- Centralityが大きいノードほど、たくさんのノード、遠いノードと接続しており重要である。
- Degree Centrality
そのノードと連結する辺の数である。
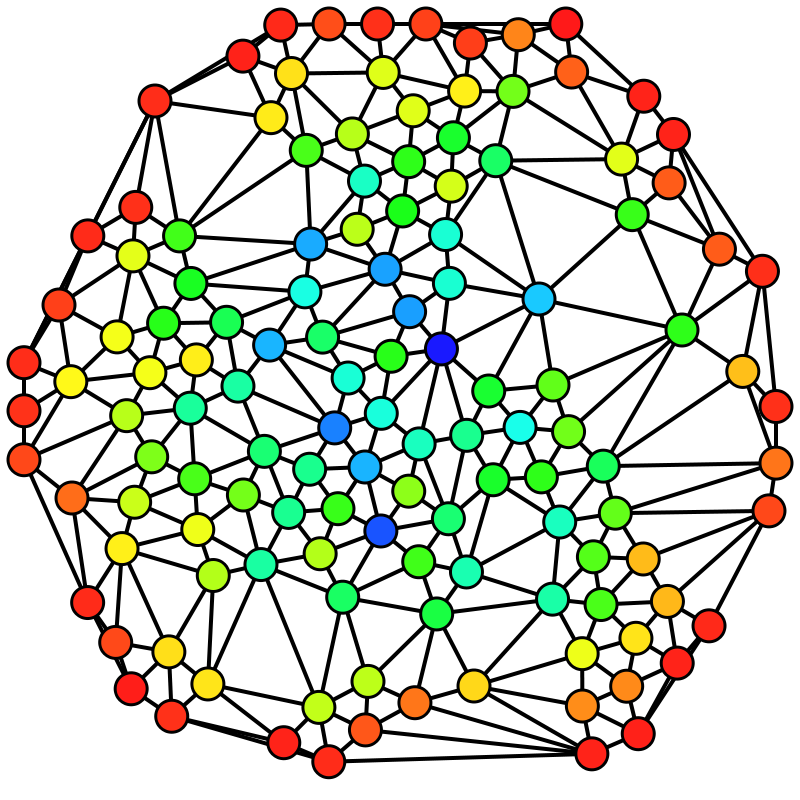
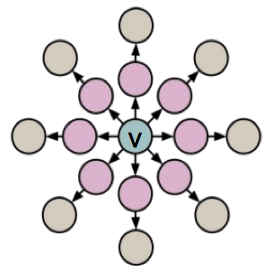
 |
図13. Betweenness Centralityの例。赤から青に向かってCentralityは大きくなる。
(Wikipediaより抜粋) |
先の1次元WLアルゴリズムの場合は、全グラフを使ってラベル値を決定するが、Centralityの場合は個々のグラフからラベル値が決まる。
4-3. ノード・シーケンス
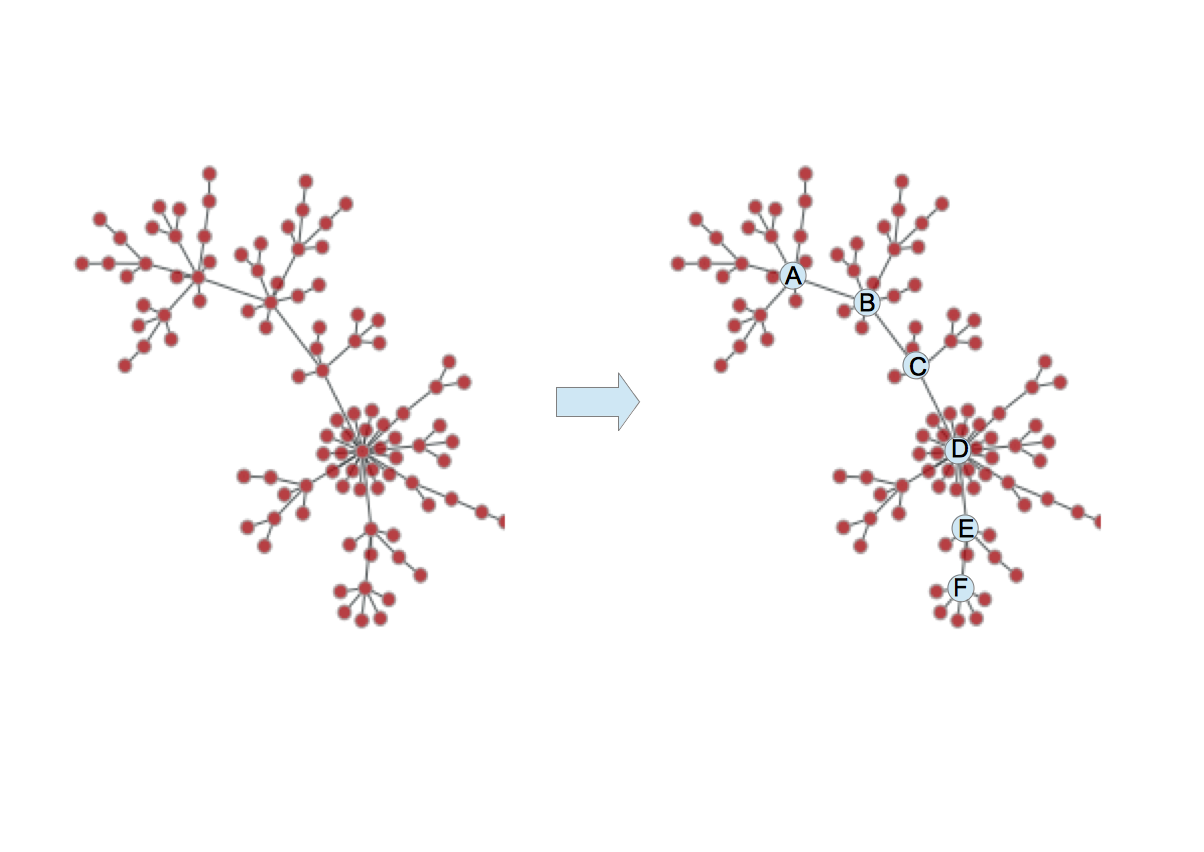
1次元WLアルゴリズムあるいはCentralityを用いて全グラフの全ノードにラベル付けを行ったあと、個々のグラフについてラベル値の大きなものから順に$w$個のノードを取り出す。これがノード・シーケンスとなる(図14)。要素数$w$は全グラフで同じである。画像の言葉で言えば、画像サイズは固定されるということである。本論文では、1つのグラフを構成するノード数の平均値を$w$としている。
 |
| 図14. {A,B,C,D,E,F}がノード・シーケンス |
ノード・シーケンスの各要素においてRFを作り、畳み込みを行う。画像におけるCNNと同様に、畳み込みを行うノード(画像の場合は画素)を$s(\neq 1)$個ずつ進めることもできる。
5. Receptive Field(RF)の決定
ノード・シーケンスの要素$v$が与えられとき、$v$を中心にしてサイズ$k$のRFを作成する。その手順は以下の通りである。
- $v$から出発して隣接ノードを順にたどり$k$個を越えたところで止める。
- 集めたノードをNormalizationする(後述)。
各手順の詳細を以下に示す。
5-1. 近傍ノードの収集
ノード$v$に対し、図15に示した順に近傍ノードを集めて行く。図16はこれをアルゴリズムにしたものである。
 |
| 図15 |
 |
| 図16. 本論文より抜粋 |
5-2. 近傍ノードのNormalization
手順は以下の通りである。
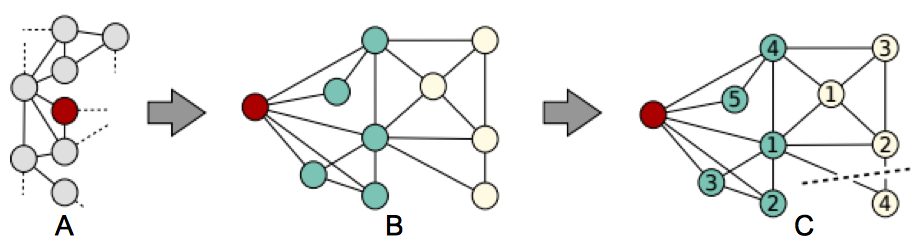
- $v$(赤丸)を中心に近傍ノードを集める(図17A)。
- $v$からの距離で色分けを行う。図17Bでは距離1と距離2で色分けを行っている。
- 距離1のノードをラベル値の降順に並べる(図17C)。同じことを距離2のノードについても行う。
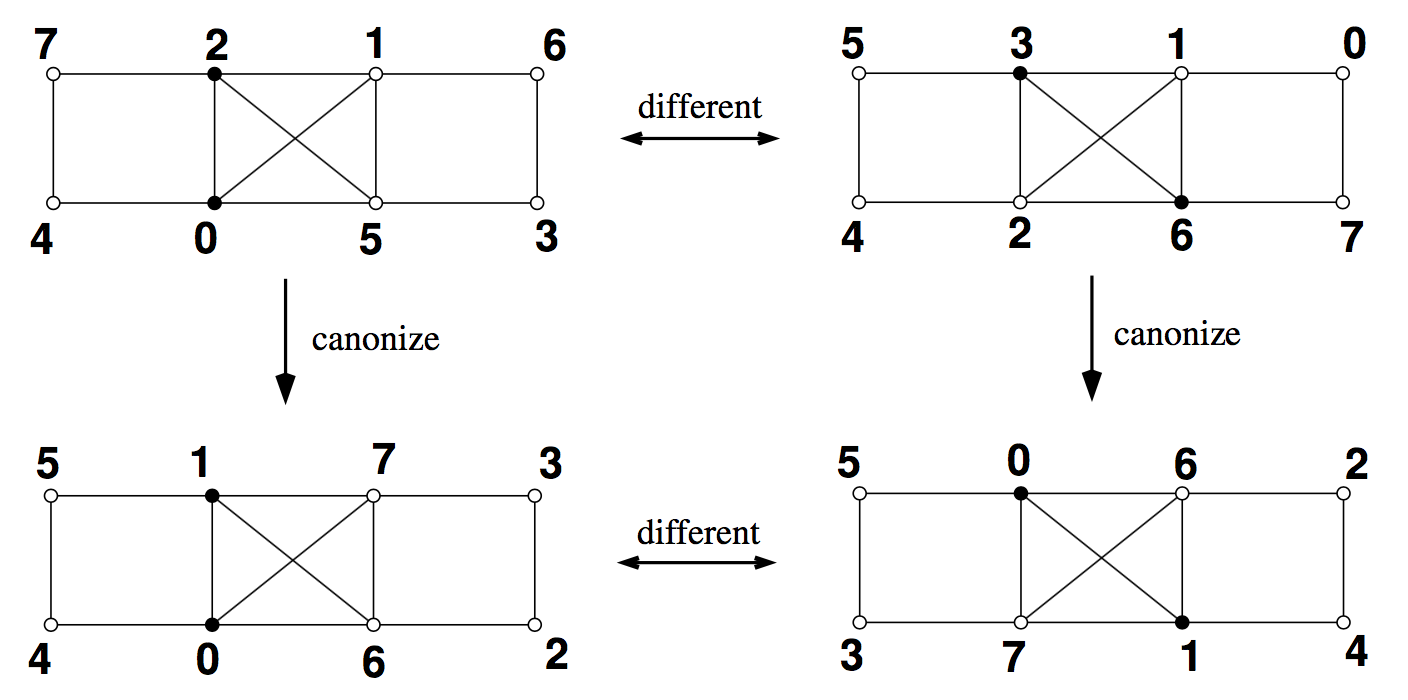
- 赤ノードを先頭に1次元に展開する(図18)。ノードの総数が$k$を越えている場合は末尾から必要なだけ削除する。$k$より少なければ0パディングする。ラベル値が同じとき1次元に展開したときの位置が一意に決まらない。この場合は、Canonicalizationを行いラベル値の縮退を解く。本論文ではNautyなるツールを用いてこれを行っている(こちらに追記しました(2017/02/26))。
 |
| 図17. 本論文より抜粋 |
 |
| 図18. 本論文より抜粋 |
各ノードに一意の並び順を与えベクトル化することをNormalizationという。図19は上記の手順をアルゴリズムとして示したものである。
 |
| 図19. 本論文より抜粋 |
6. ここまでのまとめ
図20,21は、ノード・シーケンスをたどりながらRFを作成する手順を示したものである。RFは$w$個作られる。ストライド$s(\neq 1)$でたどると$w$に達する前にノード・シーケンスの要素を使い果たすことになる。その場合は、0パディングしたRFを返す(ZeroReceptiveField())。その他の関数については既に説明した。
 |
| 図20. 本論文より抜粋 |
 |
| 図21. 図20に現れるReceptiveField関数。本論文より抜粋 |
あとは機械的にCNNを実行すればよい。
7. CNNの実行
本論文のネットワーク構造は以下の通りである。
第1層目の点線で囲んだ部分がグラフ固有の処理である。この層で、上で説明したグラフ固有の畳み込みが実行される。2層目以降は通常のCNNである。畳み込みは次式で定式化される。
\begin{equation}
g_{m,p,i}=\sum_{k,l}\;w_{p,l,k}\;x_{m,l,i+k}
\end{equation}
ここで、$p$はRFの種類、$i$はノード・シーケンスの要素番号(画像の言葉で言えば画素の位置)、$k$はRFのサイズ、$l$はチャンネル数である。また、バッチ処理を行う際、複数のノード・シーケンスを一度に扱うが、$m$はそのときのノード・シーケンスの番号である。さらに、チャンネルとは、グラフの場合、ノード属性に相当する。いま、畳み込みを記号$\otimes$で表すと上式は
\begin{equation}
g_{m,p}=\sum_{l}\;w_{p,l}\otimes x_{m,l,}
\end{equation}
と書ける。$x_{m,l}$が$g_{m,p}$に更新され、今度は、$g_{m,p}$に対して畳み込みを行うというのがCNNの一連の処理である。ここまでの議論でグラフをCNNの流れに載せることができたことになる。
8. 参考文献
- Weisfeiler-Lehman Graph Kernels
- Boosting and Semi-supervised Learning
- Centrality
- 著者らのスライド
- PFNの人のスライド