はじめに
先のページで theano を使ってシーン認識(8分類問題)を試みた。今回は、caffe を取り上げ、同じ問題に適用する。
計算環境
AmazonのEC2を利用した。インスタンス名は g2.2xlarge である。GPUを搭載したマシーンである。
データセット
データセットは前回と同じである。
| ラベル | 名前 | 枚数(train) | 枚数(test) |
|---|---|---|---|
| 0 | MITcoast | 610 | 100 |
| 1 | MIThighway | 440 | 70 |
| 2 | MITmountain | 630 | 100 |
| 3 | MITstreet | 490 | 80 |
| 4 | MITforest | 550 | 90 |
| 5 | MITinsidecity | 520 | 80 |
| 6 | MITopencountry | 690 | 110 |
| 7 | MITtallbuilding | 600 | 100 |
| 4530 | 730 |
これまでと同様に左右反転画像を追加してある。theano を用いた時は、データセットを train / validation / test の3つに分けたが、今回は train と validation を1つにまとめ改めて train とした。また、画像サイズは 126$\times$126 に変更し、画像の枚数も10で割り切れるよう調節した。
caffe用データの作成
caffeが必要とするものは以下の4つである。
- train 画像を納めたディレクトリへのパス
- test 画像を納めたディレクトリへのパス
- train 画像名とラベルを記したテキストファイル
- test 画像名とラベルを記したテキストファイル
- /home/ubuntu/data/caffe/train
- /home/ubuntu/data/caffe/test
- /home/ubuntu/data/caffe/train.txt
- /home/ubuntu/data/caffe/test.txt
test.txt
MITtallbuilding_image_0332_flipped.jpg 7train.txt
MITopencountry_image_0195.jpg 6
MITstreet_image_0176_flipped.jpg 3
MITmountain_image_0042.jpg 2
MITcoast_image_0195.jpg 0
MITmountain_image_0063_flipped.jpg 2
MITopencountry_image_0366_flipped.jpg 6
MITmountain_image_0229.jpg 2
MITtallbuilding_image_0354_flipped.jpg 7
MITforest_image_0086.jpg 4
MITcoast_image_0085.jpg 0
MITstreet_image_0094.jpg 3
MITopencountry_image_0401.jpg 6
MITmountain_image_0025_flipped.jpg 2
MITcoast_image_0075_flipped.jpg 0
MITforest_image_0227_flipped.jpg 4
....
MITstreet_image_0253_flipped.jpg 3ディレクトリ内にテキストファイルに記述した画像を納め、以下のコマンドにより caffe 用の入力データを作成する。 以下の場所にデータベース test_leveldb と train_leveldb が出力される。
MITcoast_image_0023.jpg 0
MITstreet_image_0256_flipped.jpg 3
MIThighway_image_0228_flipped.jpg 1
MITopencountry_image_0045_flipped.jpg 6
MITmountain_image_0314.jpg 2
MITtallbuilding_image_0078.jpg 7
MITmountain_image_0337.jpg 2
MITforest_image_0120.jpg 4
MITcoast_image_0088.jpg 0
MITmountain_image_0211_flipped.jpg 2
MITforest_image_0133_flipped.jpg 4
MITcoast_image_0356.jpg 0
MIThighway_image_0081_flipped.jpg 1
MITcoast_image_0115_flipped.jpg 0
MITmountain_image_0218_flipped.jpg 2
MITforest_image_0196_flipped.jpg 4
MITforest_image_0281_flipped.jpg 4
...
ネットワークの設計
ここでは、caffeのサンプル(caffe-master/examples/mnist/lenet_train_test.prototxt)を下敷きにして以下のようなネットワーク構造を定義した(scene_train_test.prototxt)。
solverの作成
訓練を行なうためのテキストファイル scene_solver.prototxt を以下のように記述する。caffe の提供するサンプルファイル(caffe-mater/examples/mnist/lenet_solver.prototxt)を下敷きにした。 現在の test 画像の枚数は730枚、batch size を10としたので73回で一通り画像を走査することになる。従って、73回ごとに正解率を出力するようにした。
訓練
以下を実行する。
結果
以下に結果を示す。
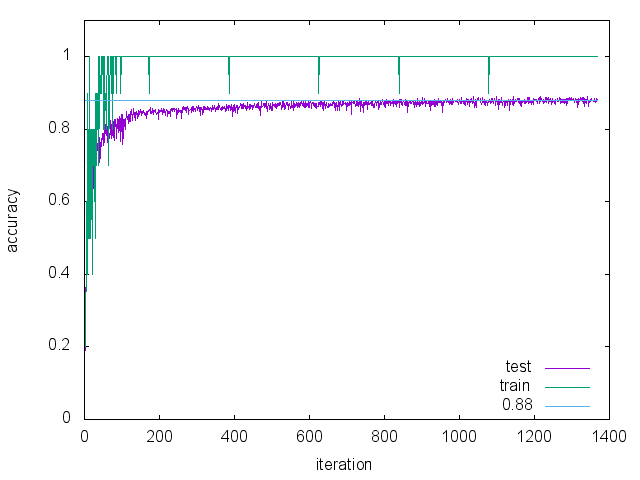
検出器の作成
ここまでの計算で、ファイル snapshot_iter_100000.caffemodel ができている。ここには、訓練によりパラメータの確定したネットワーク構造が納められている。このファイルから検出器を作るには、以下のようなdeploy.prototxt ファイル(ここではscene_deploy.prototxtとした)が必要である。 これは、先に定義した scene_train_test.prototxt のデータ層を取り除き を追加し、最終層にある loss 層と accuracy 層を取り除き を追加したものである。データ層の代わりに挿入した input_dim の意味は以下の通りである。
- input_dim: 10 --- バッチサイズ
- input_dim: 1 --- 入力画像のチャンネル数
- input_dim: 126 --- 入力画像の幅
- input_dim: 126 --- 入力画像の高さ