Introduction
In this page, a 3D object recognition is performed by means of the library Caffe. The algorithm which is proposed here is based on the work of H. Su et al.. It is shown that with the pre-trained model that Caffe provides and its fine-tuning by the ModelNet10 dataset, the recognition accuracy achieves about 90.2% .
Computation Environment
An instance "g2.2xlarge" in the Amazon EC2 is used. It mounts the GPU device on which the CUDA driver is installed.
Dataset
The CNN model (bvlc_reference_caffenet.caffemodel) that Caffe provides is fine-tuned using the ModelNet10 dataset which consists of 10 categories as follows:
- bathtub
- bed
- chair
- desk
- dresser
- monitor
- night stand
- sofa
- table
- toilet

| label | name | the number of trainings | the number of testings |
|---|---|---|---|
| 0 | bathtub | 106 | 50 |
| 1 | bed | 515 | 100 |
| 2 | chair | 889 | 100 |
| 3 | desk | 200 | 86 |
| 4 | dresser | 200 | 86 |
| 5 | monitor | 465 | 100 |
| 6 | night stand | 200 | 86 |
| 7 | sofa | 680 | 100 |
| 8 | table | 392 | 100 |
| 9 | toilet | 344 | 100 |
| 3991 | 908 |
Training Algorithm
The following procedures are applied to the training 3D models.
- A 3D model is loaded.
- It is scaled to such an appropriate size that all models have the same size.
- The centroid is calculated.
- A regular dodecahedron is placed centering around the centroid.
- 20 depth images (400$\times$400 pixels) are drawn by making the 20 vertices of the dodecahedron view points.
- The images are converted to gray images with the range [0,255].
- The 20 gray images are obtained per model. Those images have the same label.
- The pre-trained CNN model that Caffe provides is fine-tunued by them.
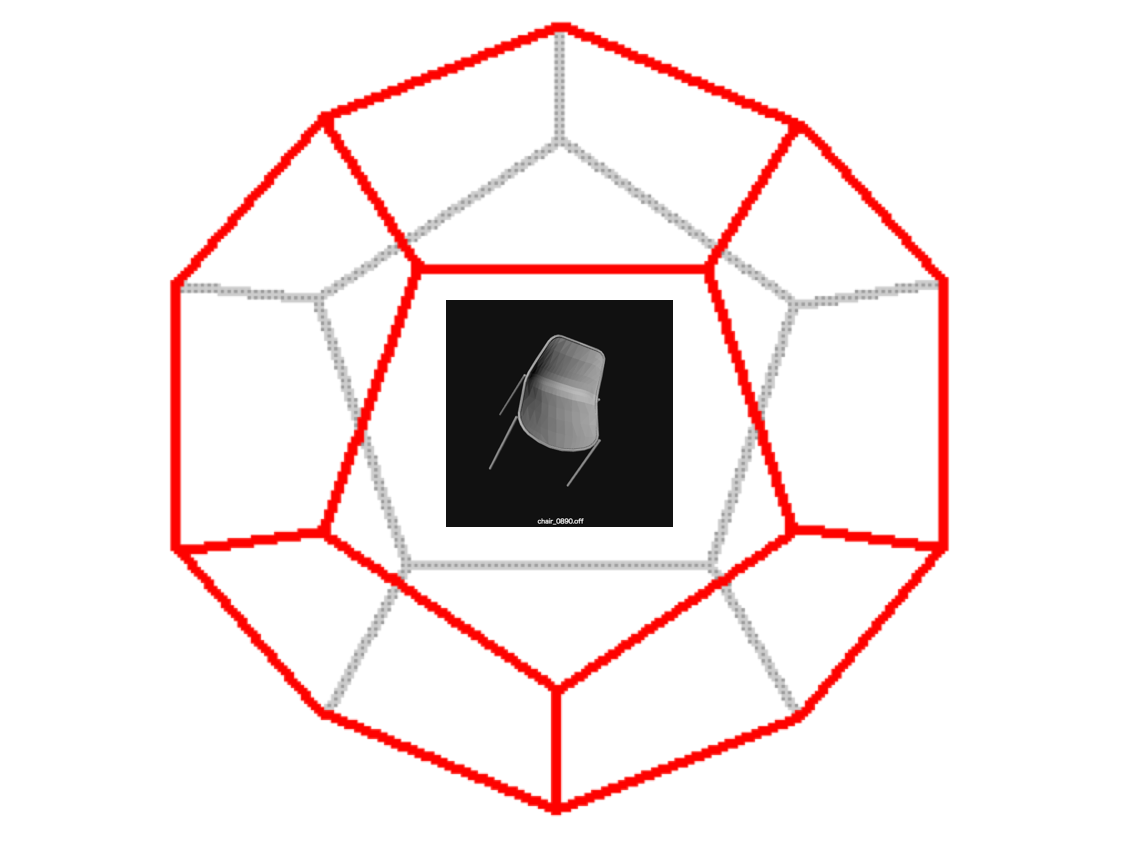

| the number of trainings | the number of testings | |
|---|---|---|
| 3D model | 3991 | 908 |
| gray image ($\times$20) | 79820 | 18160 |
Prediction Algorithm
The following procedures are applied to the testing 3D models:
- A 3D model is loaded.
- It was scaled to such an appropriate size that all models have the same size.
- The centroid is calculated.
- A regular dodecahedron is placed centering around the centroid.
- 20 depth images (400$\times$400 pixels) are drawn by making the 20 vertices of the dodecahedron view points.
- The images are converted to gray images with the range [0,255].
- The 20 gray images are obtained per model.
- The above fine-tuned CNN is applied to the 20 gray images.
- The 20 labels are obtained.
- The resultant label is decided by majority vote.

Dataset for Caffe
Caffe requires the following directories and files:
- a directory which contains training images
- a directory which contains testing images
- a text file in which names and labels of training images are described
- a text file in which names and labels of testing images are described
desk_0234_depth_image_0.png 3The contents of "train.txt" are as follows:
night_stand_0224_depth_image_0.png 6
chair_0904_depth_image_0.png 2
desk_0208_depth_image_0.png 3
bathtub_0127_depth_image_0.png 0
monitor_0528_depth_image_0.png 5
desk_0241_depth_image_0.png 3
dresser_0285_depth_image_0.png 4
sofa_0751_depth_image_0.png 7
dresser_0218_depth_image_0.png 4
....
chair_0190_depth_image_0.png 2After storing the images specified in "test.txt" and "train.txt" in the directories "ModelNet10Test" and "ModelNet10Train" respectively, this script is run to create a dataset for Caffe. "test_lmdb" and "train_lmdb" which are inputs for Caffe are output.
sofa_0138_depth_image_0.png 7
chair_0019_depth_image_0.png 2
dresser_0086_depth_image_0.png 4
table_0232_depth_image_0.png 8
sofa_0097_depth_image_0.png 7
night_stand_0040_depth_image_0.png 6
chair_0501_depth_image_0.png 2
chair_0766_depth_image_0.png 2
bed_0370_depth_image_0.png 1
...
Definition of CNN
The CNN model is defined in the file "train_val.prototxt" as The file is based on the file "bvlc_reference_caffenet/train_val.prototxt" that Caffe provides. The differences between the original and my own files exists in two layers, "data" and "fc8." In accordance with the interpretation in this page, parameters in the layer "3dobject_fc8" are modified as shown above.
Definition of Solver
Based on the file "bvlc_reference_caffenet/solver.prototxt," the file used for fine-tuning the CNN is written as, The file is named "solver.prototxt."
Training
This script is run to fine-tune the CNN model. The pre-trained model which Caffe provides is "bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel" which is passed to "caffe train" command as the argument of the "-weights." That script fine-tunes the pre-trained model by using the current dataset.
Result

Construction of Classifier
After training, a file "3dobject_train_iter_100000.caffemodel" is created. It is called a model file. The file contains the information on the fine-tuned CNN. In order to construct a classifier from the model file, the following file is also needed. That file is named "deploy.ptototxt." To get it, "train_val.prototxt" previously defined is modified according to the following procedures.
- Remove the layer "data," and add following four lines.
- Remove the layers "loss" and "accuracy", and add this layer.
- input_dim: 20 --- batch size
- input_dim: 3 --- channel number
- input_dim: 227 --- width of an image
- input_dim: 227 --- height of an image
Comparison With Other Works
The following table is quoted from the Princeton ModelNet page. The algorithm proposed here is not bad in spite of the simple procedures.
| Algorithm | Accuracy |
|---|---|
| VoxNet | 92% |
| DeepPano | 85.45% |
| 3DShapeNets | 83.5% |
| the proposed algorithm | 90.2% |
References
- D. Maturana and S. Scherer. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. IROS2015.
- B Shi, S Bai, Z Zhou, X Bai. DeepPano: Deep Panoramic Representation for 3-D Shape Recognition. Signal Processing Letters 2015.
- Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang and J. Xiao. 3D ShapeNets: A Deep Representation for Volumetric Shapes. CVPR2015.
- Hang Su, Subhransu Maji, Evangelos Kalogerakis, and Erik Learned-Miller, Multi-view Convolutional Neural Networks for 3D Shape Recognition