はじめに
先の2回の投稿(こことここ)では、Variational Auto Encoder(VAE)をBayes推論の枠組みで解説した。今回は、Conditional Variational Auto Encoder(CAVE)をBayes推論の枠組みで説明する。
問題設定
回帰問題を考え、$N$個のペア$(\vec{x}_n, \vec{y}_n)$が観測されているとする。$X=\{\vec{x}_1,\cdots,\vec{x}_N\}, Y=\{\vec{y}_1,\cdots,\vec{y}_N\}$と置いたとき、未観測データ$\vec{x}_{\alpha}$に対応する$\vec{y}_{\alpha}$を生成する確率分布$p(\vec{y}_{\alpha}|\vec{x}_{\alpha},X,Y)$を求めたい。潜在変数$\vec{z}$を導入し、$X$、$Y$、$\vec{z}$の同時確率分布$p(X,Y,\vec{z})$を考え、Bayesの定理を適用すると次式を得る。 \begin{equation} p(\vec{z}|X,Y) = \frac{p(Y|X,\vec{z})p(\vec{z})}{p(Y|X)} \label{eq9} \end{equation} ただし、式変形の途中で$p(X|\vec{z})=p(X)$を用いた。事後確率$p(\vec{z}|X,Y)$が求まれば、次式により$\vec{y}_{\alpha}$を生成する確率分布を求めることができる。 \begin{equation} p(\vec{y}_{\alpha}|\vec{x}_{\alpha},X,Y)=\int d\vec{z}\;p(\vec{y}_{\alpha}|\vec{x}_{\alpha},\vec{z})p(\vec{z}|X,Y) \label{eq3} \end{equation} 事後確率$p(\vec{z}|X,Y)$を求めることが目的である。
最適化すべき量
$p(\vec{z}|X,Y)$を直接求めることはせず、パラメータ$\phi$を持つ関数$q_{\phi}(\vec{z}|X,Y)$を導入し、次のKullback Leibler divergenceを最小にすることを考える。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}|X,Y) \right]=\int d\vec{z}\;q_{\phi}(\vec{z}|X,Y) \ln{ \frac{ q_{\phi}(\vec{z}|X,Y) } { p(\vec{z}|X,Y) } } \end{equation} これを変形すると次式を得る。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}|X,Y) \right] = D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}) \right]-E_{q_{\phi}(\vec{z}|X,Y)}\left[\ln{p(Y|X,\vec{z})}\right]+\ln{p(Y|X)} \label{eq1} \end{equation} ただし、式変形の途中で式(\ref{eq9})を用いた。式(\ref{eq1})右辺にある$\ln{p(Y|X)}$は$\phi$に依存せず、観測値だけから決まる定数である。従って、次式が成り立つ。 \begin{equation} \min_{\phi} D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}|X,Y) \right] = \min_{\phi} {\left[ D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}) \right]-E_{q_{\phi}(\vec{z}|X,Y)}\left[\ln{p(Y|X,\vec{z})}\right] \right] } \label{eq2} \end{equation} 式(\ref{eq2})の右辺第1項を小さく、第2項の期待値を大きくすれば良い。第1項は$q_{\phi}(\vec{z}|X,Y)$をできるだけ$p(\vec{z})$に近い形の分布にすることを要求し、この分布の下で対数尤度$\ln{p(Y|X,\vec{z})}$の期待値を大きくすることを第2項は要求する。第1項は正則化項に相当する。
KL divergenceの計算
式(\ref{eq2})の右辺第1項を考える。いま次の仮定をおく。 \begin{eqnarray} q_{\phi}(\vec{z}|X,Y)&=&\mathcal{N}(\vec{z}|\vec{\mu}_{\phi}(X,Y),\Sigma_{\phi}(X,Y)) \\ p(\vec{z})&=&\mathcal{N}(\vec{z}|\vec{0},I_D) \end{eqnarray} ここで、$\vec{z}$の次元を$D$とした。$I_D$は$D\times D$の単位行列である。どちらの分布も正規分布とし、$q_{\phi}(\vec{z}|X,Y)$の平均と共分散行列は$\phi,X,Y$から決まる量とする。これらは、入力$X,Y$、パラメータ$\phi$のニューラルネットワークを用いて計算される。一方、$p(\vec{z})$の方は平均0、分散1の標準正規分布である。このとき、$D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}) \right]$は解析的に計算することができる。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}) \right]=\frac{1}{2}\left[ -\ln{|\Sigma_{\phi}(X,Y)|} -D +\mathrm{Tr}\left(\Sigma_{\phi}(X,Y)\right)+\vec{\mu}_{\phi}(X,Y)^T\vec{\mu}_{\phi}(X,Y) \right] \label{eq4} \end{equation}
ここまでの処理の流れ
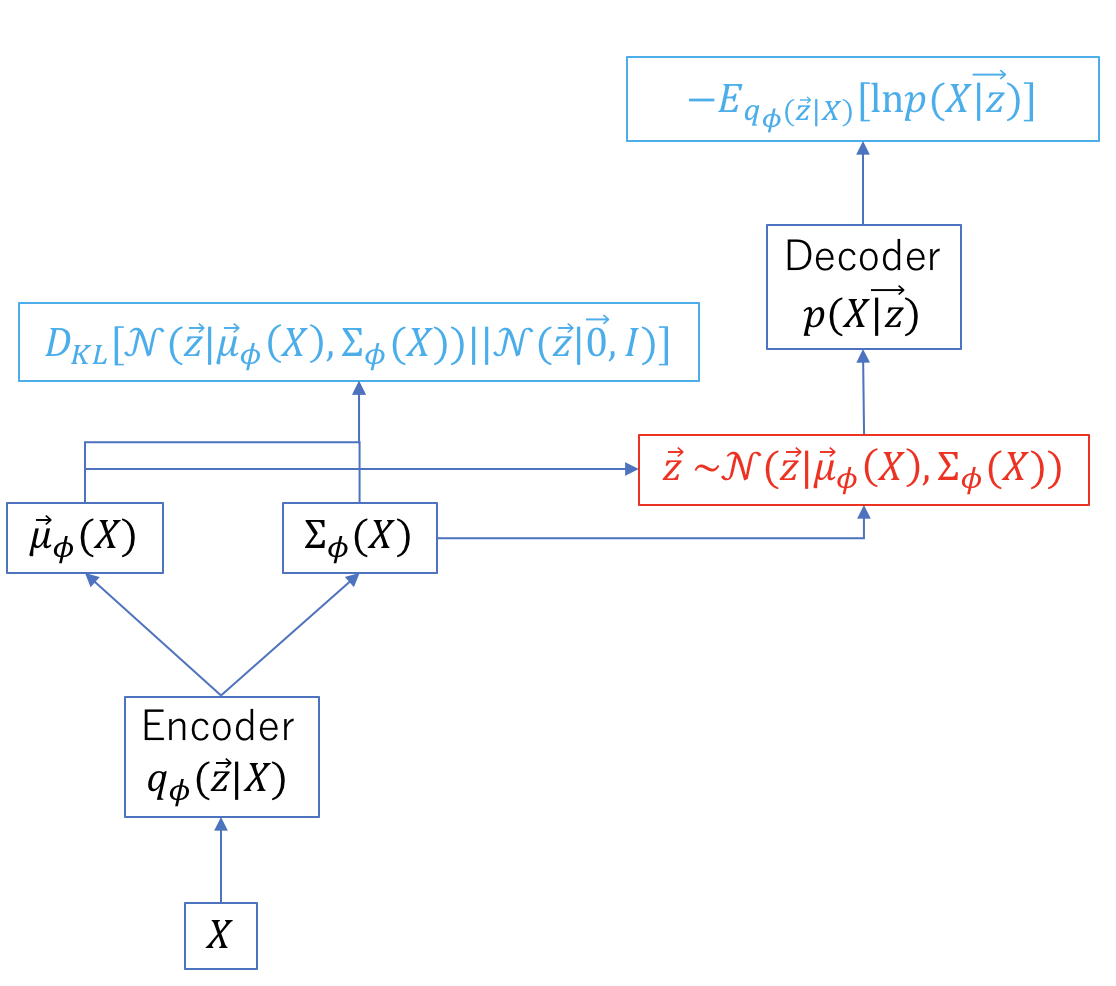
式(\ref{eq2})を計算する際の手順は以下のようになる。

分布$q_{\phi}(\vec{z}|X,Y)$は$X$と$Y$から$\vec{z}$を生成するEncoder、$p(Y|X,\vec{z})$は$X$と$\vec{z}$から$Y$を生成するDecoderとみなすことができる。青色で示した部分は最小化すべき量であり、赤字はサンプリングするステップである。青色の式の和を勾配降下法により最小にするが、その際、誤差逆伝播ができなければならない。$q_{\phi}(\vec{z}|X,Y)$はその$\phi$依存性のため誤差逆伝播時の微分鎖の中に組み込まれるが、サンプリングという処理の勾配を定義することができない。対数尤度の期待値の計算に工夫が必要である。
対数尤度の期待値の計算
計算したい式は次式である。 \begin{equation} E_{q_{\phi}(\vec{z}|X,Y)}\left[\ln{p(Y|X,\vec{z})}\right]=\int d\vec{z}\;q_{\phi}(\vec{z}|X,Y)\ln{p(Y|X,\vec{z})} \end{equation} この式に再パラメータ化トリック(re-parametrization trick)を適用する。すなわち \begin{equation} \vec{z}\sim\mathcal{N}(\vec{z}|\vec{\mu}_{\phi}(X,Y),\Sigma_{\phi}(X,Y)) \end{equation} の代わりに \begin{eqnarray} \vec{\epsilon}&\sim&\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\\ \vec{z}&=& \vec{\mu}_{\phi}(X,Y)+\Sigma_{\phi}^{1/2}(X,Y)\vec{\epsilon} \label{eq7} \end{eqnarray} を用いてサンプリングを行う。これを用いて期待値を書き直すと次式を得る。 \begin{equation} E_{q_{\phi}(\vec{z}|X,Y)}\left[\ln{p(Y|X,\vec{z})}\right]=\int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\ln{p(Y|X, \vec{z}=\vec{\mu}_{\phi}(X,Y)+\Sigma_{\phi}^{1/2}(X,Y)\vec{\epsilon})} \label{eq11} \end{equation} 処理の流れは以下のように変更される。

上図であれば誤差逆伝播が可能となる。
未観測データの生成
未観測データ$\vec{y}_{\alpha}$を生成する確率分布は次式で与えられた。 \begin{equation} p(\vec{y}_{\alpha}|\vec{x}_{\alpha},X,Y)=\int d\vec{z}\;p(\vec{y}_{\alpha}|\vec{x}_{\alpha},\vec{z})p(\vec{z}|X,Y) \end{equation} 事後確率$p(\vec{z}|X,Y)$の近似解$q_{\phi}(\vec{z}|X,Y)$を用いると \begin{equation} p(\vec{y}_{\alpha}|\vec{x}_{\alpha},X,Y)\approx\int d\vec{z}q_{\phi}(\vec{z}|X,Y)p(\vec{y}_{\alpha}|\vec{x}_{\alpha},\vec{z}) \end{equation} を得る。先と同様に再パラメータ化トリックを適用すると \begin{equation} p(\vec{y}_{\alpha}|\vec{x}_{\alpha},X,Y)\approx\int d\vec{\epsilon}\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)p(\vec{y}_{\alpha}|\vec{x}_{\alpha}, \vec{z}=\vec{\mu}_{\phi}(X,Y)+\Sigma_{\phi}^{1/2}(X,Y)\vec{\epsilon}) \label{eq10} \end{equation} となる。
実装に向けた詳細な計算
最初に$\vec{\mu}_{\phi}(X,Y)$と$\Sigma_{\phi}(X,Y)$を次のように置く。 \begin{eqnarray} \vec{\mu}_{\phi}(X,Y)&=&(\mu_{\phi,1}(X,Y),\cdots,\mu_{\phi,D}(X,Y))^T \label{eq5}\\ \Sigma_{\phi}(X,Y)&=&\mathrm{diag}(\sigma^2_{\phi,1}(X,Y),\cdots,\sigma^2_{\phi,D}(X,Y)) \label{eq6} \end{eqnarray} このとき式(\ref{eq4})は次式となる。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X,Y)||p(\vec{z}) \right]= \frac{1}{2} \sum_{d=1}^{D}\left\{ -\ln{\sigma^2_{\phi,d}(X,Y)}-1+\sigma^2_{\phi,d}(X,Y)+\mu_{\phi,d}^2(X,Y) \right\} \label{eq8} \end{equation} また、$\vec{z}$の成分は次式で与えられる。 \begin{equation} z_d=\mu_{\phi,d}(X,Y)+\sigma_{\phi,d}(X,Y)\epsilon_d \end{equation} 観測値が独立同分布に従うと仮定すると、式(\ref{eq11})の中にある対数尤度は以下のように変形される。 \begin{equation} \ln{p(Y|X,\vec{z})}= \sum^{N}_{n=1}\ln{p(\vec{y}_n|\vec{x}_n,\vec{z})} \end{equation} さらに計算を進めるには、具体的に$X,Y$として、何を与えるか決定しなければならない。 ここでは、$X$として0から9までのラベルを、$Y$としてMNISTの画像(2値画像)を与えることにする。$X$の各観測値$\vec{x}_n$は$9$次元のone-hotベクトルで表現される。各画素が独立同分布に従うと仮定すると、$\vec{y}_n$の次元数を$M$として \begin{equation} \ln{p(\vec{y}_n|\vec{x}_n,\vec{z})}=\sum_{m=1}^{M}\ln{p(y_{n,m}|\vec{x}_n,\vec{z})} \end{equation} と書くことができる。いま考える画像は0と1から構成されるから、$p(y_{n,m}|\vec{x}_n,\vec{z})$として0と1を生成するBernoulli分布を仮定する。 \begin{eqnarray} p(y_{n,m}|\vec{x}_n,\vec{z})&=&\mathrm{Bern}\left(y_{n,m}|\eta_{\theta,m}\left(\vec{x}_n,\vec{z}\right)\right) \\ \mathrm{Bern}(x|\eta)&=&\eta^{x}(1-\eta)^{1-x} \end{eqnarray} $\eta_{\theta,m}\left(\vec{x}_n,\vec{z}\right)$は、入力が$\vec{x}_n$と$\vec{z}$、パラメータとして$\theta$を持つニューラルネットワークで学習される。以上を踏まえて処理の流れを書き直すと下図となる。

次に式(\ref{eq10})を考える。これは、観測値$X,Y$とラベル$\vec{x}_{\alpha}$が与えられときの$\vec{y}_{\alpha}$の実現確率である。 \begin{equation} p(\vec{y}_{\alpha}|\vec{x}_{\alpha},X,Y)\approx \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;p(\vec{y}_{\alpha}|\vec{x}_{\alpha},\vec{z}) \end{equation} ここで、$z_d=\mu_{\phi,d}(X)+\sigma_{\phi,d}(X)\epsilon_d$である。上式は以下のように書くことができる。 \begin{equation} \prod_{m=1}^M p(y_{\alpha,m}|\vec{x}_\alpha,X,Y)\approx \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;\prod_{m=1}^M p(y_{\alpha,m}|\vec{x}_\alpha,\vec{z}) \end{equation} すなわち、要素$y_{\alpha,m}$ごとに次式が成り立つ。 \begin{equation} p(y_{\alpha,m}|\vec{x}_\alpha,X,Y)\approx \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;p(y_{\alpha,m}|\vec{x}_\alpha,\vec{z}) \end{equation} $p(y_{\alpha,m}|\vec{x}_\alpha,\vec{z})$としてBernoulli分布を仮定したから \begin{equation} p(y_{\alpha,m}|\vec{x}_\alpha,X,Y)\approx \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;\mathrm{Bern}(y_{\alpha,m}|\eta_{\theta,m}(\vec{x}_\alpha,\vec{z})) \end{equation} となる。確率分布$p(y_{\alpha,m}|\vec{x}_\alpha,X,Y)$の下での$y_{\alpha,m}$の期待値は \begin{eqnarray} <y_{\alpha,m}>&=&\sum_{y_{\alpha,m}=0,1} y_{\alpha,m}\;p(y_{\alpha,m}|\vec{x}_\alpha,X,Y) \\ &\approx& \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;\sum_{y_{\alpha,m}=0,1} y_{\alpha,m} \mathrm{Bern}(y_{\alpha,m}|\eta_{\theta,m}(\vec{x}_\alpha,\vec{z})) \\ &=& \int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\;\eta_{\theta,m}(\vec{x}_\alpha,\vec{z}) \end{eqnarray} となる。$\vec{z}$は$\vec{\epsilon}$に依存する項であることに注意する。$\eta_{\theta,m}(\vec{x}_\alpha,\vec{z})$はDecoderの出力である。上式から、復号化した結果を得るには、$\eta_{\theta,m}(\vec{x}_\alpha,\vec{z})$を標準正規分布に従ってサンプリングすれば良いことが分かる。さらに、式(\ref{eq8})のKullback Leibler divergenceを十分小さくできれば、すなわち、$\sigma_{\phi,d}(X,Y)\rightarrow 1,\mu_{\phi,d}(X,Y)\rightarrow 0$とできれば、$\vec{z}=\vec{\epsilon}$とすることができるので、標準正規分布から生成した値$\vec{\epsilon}$と$\vec{x}_\alpha$からDecoderの出力を直接得ることができる。
まとめ
今回は、CVAEをBayes推定の枠組みで説明した。前回のVAEの論法とほとんど同じである。VAEでは未観測データ$\vec{x}$が従う確率分布$p(\vec{x}|X)$を求める過程でVAEの構造を見出した。一方、CVAEでは未観測データ$\vec{x}$に対応する$\vec{y}$が従う確率分布$p(\vec{y}|\vec{x},X,Y)$を求める過程でCVAEの構造が現れることを見た。その構造は、VAEに少し手を加えれば実現できる程度のものである。ChainerのVAEのサンプルコードをベースにすればすぐに実装できそうである。