はじめに
Variational Auto Encoder(VAE)をBayes推論の枠組みで解説し、Chainerのサンプルコードを読解する。
問題設定
観測値$X=\{\vec{x}_1,\cdots,\vec{x}_N\}$が与えられたとき、未知の値$\vec{x}_*$を生成する確率分布$p(\vec{x}_*|X)$を求めたい。潜在変数$\vec{z}$を導入し、$X$と$\vec{z}$の同時確率分布$p(X,\vec{z})$を考え、Bayesの定理を適用すると次式を得る。 \begin{equation} p(\vec{z}|X) = \frac{p(X|\vec{z})p(\vec{z})}{p(X)} \label{eq9} \end{equation} 事後確率$p(\vec{z}|X)$が求まれば、次式により$\vec{x}_*$を生成する確率分布を求めることができる。 \begin{equation} p(\vec{x}_*|X)=\int d\vec{z}\;p(\vec{x}_*|\vec{z})p(\vec{z}|X) \label{eq3} \end{equation} 事後確率$p(\vec{z}|X)$を求めることが目的である。
最適化すべき量
$p(\vec{z}|X)$を直接求めることはせず、パラメータ$\phi$を持つ関数$q_{\phi}(\vec{z}|X)$を導入し、次のKullback Leibler divergenceを最小にすることを考える。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}|X) \right]=\int d\vec{z}\;q_{\phi}(\vec{z}|X) \ln{ \frac{ q_{\phi}(\vec{z}|X) } { p(\vec{z}|X) } } \end{equation} これを変形すると次式を得る。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}|X) \right] = D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]-E_{q_{\phi}(\vec{z}|X)}\left[\ln{p(X|\vec{z})}\right]+\ln{p(X)} \label{eq1} \end{equation} ただし、式変形の途中で式(\ref{eq9})を用いた。式(\ref{eq1})右辺にある$\ln{p(X)}$は$\phi$に依存せず、観測値だけから決まる定数である。従って、次式が成り立つ。 \begin{equation} \min_{\phi} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}|X) \right] = \min_{\phi} {\left[ D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]-E_{q_{\phi}(\vec{z}|X)}\left[\ln{p(X|\vec{z})}\right] \right] } \label{eq2} \end{equation} 式(\ref{eq2})の右辺第1項を小さく、第2項の期待値を大きくすれば良い。第1項は$q_{\phi}(\vec{z}|X)$をできるだけ$p(\vec{z})$に近い形の分布にすることを要求し、この分布の下で対数尤度$\ln{p(X|\vec{z})}$の期待値を大きくすることを第2項は要求する。第1項は正則化項に相当する。
KL divergenceの計算
式(\ref{eq2})の右辺第1項を考える。いま次の仮定をおく。 \begin{eqnarray} q_{\phi}(\vec{z}|X)&=&\mathcal{N}(\vec{z}|\vec{\mu}_{\phi}(X),\Sigma_{\phi}(X)) \\ p(\vec{z})&=&\mathcal{N}(\vec{z}|\vec{0},I_D) \end{eqnarray} ここで、$\vec{z}$の次元を$D$とした。$I_D$は$D\times D$の単位行列である。どちらの分布も正規分布とし、$q_{\phi}(\vec{z}|X)$の平均と共分散行列は$\phi$と$X$から決まる量とする。これらは、入力$X$、パラメータ$\phi$のニューラルネットワークを用いて計算される。一方、$p(\vec{z})$の方は平均0、分散1の標準正規分布である。このとき、$D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]$は解析的に計算することができる。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]=\frac{1}{2}\left[ -\ln{|\Sigma_{\phi}(X)|} -D +\mathrm{Tr}\left(\Sigma_{\phi}(X)\right)+\vec{\mu}_{\phi}(X)^T\vec{\mu}_{\phi}(X) \right] \label{eq4} \end{equation}
ここまでの処理の流れ
式(\ref{eq2})の最適化を行う際に勾配降下法を用いる。処理の流れは以下のようになる(下図参照)。
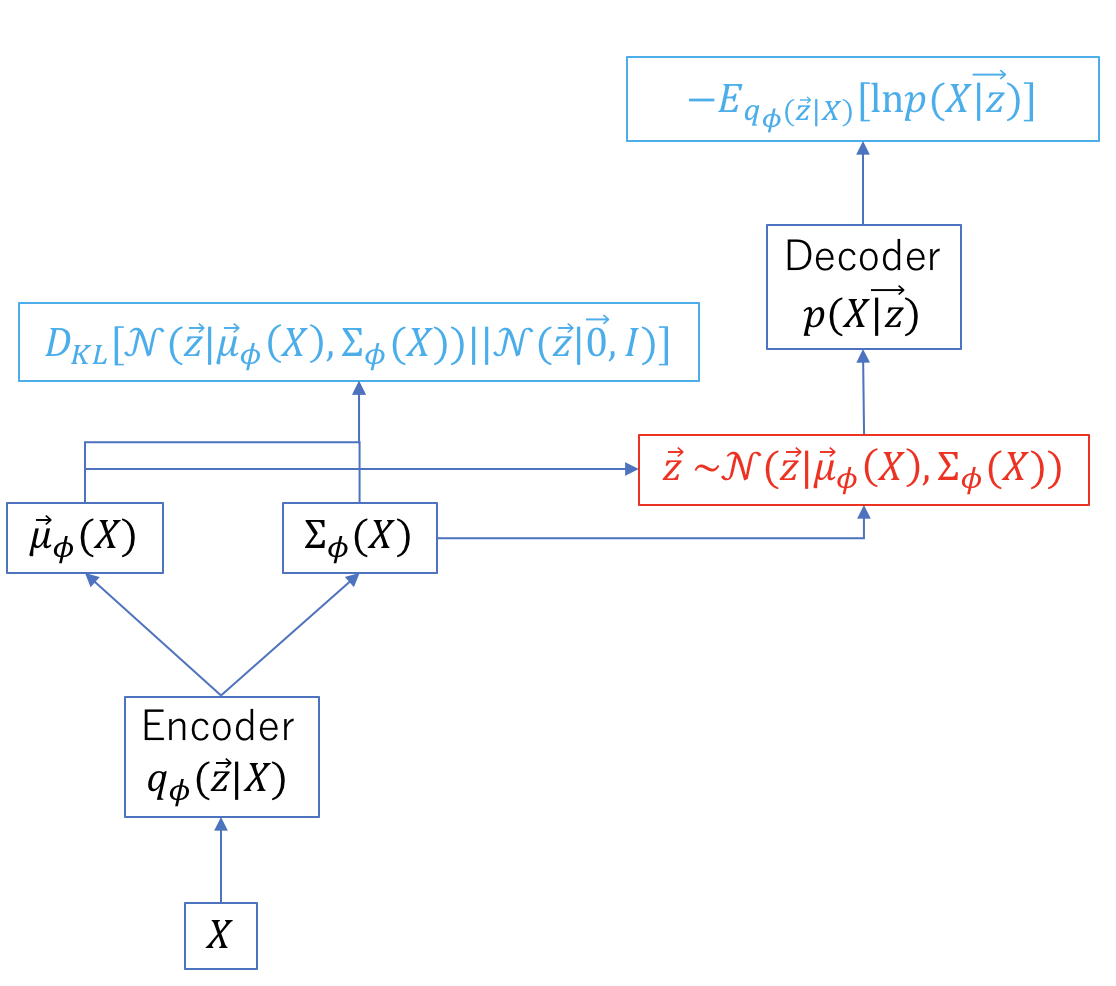
分布$q_{\phi}(\vec{z}|X)$は$X$から$\vec{z}$を生成するEncoder、$p(X|\vec{z})$は$\vec{z}$から$X$を生成するDecoderとみなすことができる。青色で示した部分は最小化すべき量であり、赤字はサンプリングするステップである。勾配降下法を実現するには、誤差逆伝播ができなければならない。$q_{\phi}(\vec{z}|X)$はその$\phi$依存性のため誤差逆伝播時の微分鎖の中に組み込まれるが、サンプリグという処理の勾配を定義することができない。対数尤度の期待値の計算に工夫が必要である。
対数尤度の期待値の計算
計算したい式は次式である。 \begin{equation} E_{q_{\phi}(\vec{z}|X)}\left[\ln{p(X|\vec{z})}\right]=\int d\vec{z}\;q_{\phi}(\vec{z}|X)\ln{p(X|\vec{z})} \end{equation} この式に再パラメータ化トリック(re-parametrization trick)を適用する。すなわち \begin{equation} \vec{z}\sim\mathcal{N}(\vec{z}|\vec{\mu}_{\phi}(X),\Sigma_{\phi}(X)) \end{equation} の代わりに \begin{eqnarray} \vec{\epsilon}&\sim&\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\\ \vec{z}&=& \vec{\mu}_{\phi}(X)+\Sigma_{\phi}^{1/2}(X)\vec{\epsilon} \label{eq7} \end{eqnarray} を用いてサンプリングを行う。これを用いて期待値を書き直すと次式を得る。 \begin{equation} E_{q_{\phi}(\vec{z}|X)}\left[\ln{p(X|\vec{z})}\right]=\int d\vec{\epsilon}\;\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)\ln{p(X| \vec{z}=\vec{\mu}_{\phi}(X)+\Sigma_{\phi}^{1/2}(X)\vec{\epsilon})} \end{equation} このときの処理の流れは以下のようになる(下図参照)。

上図であれば誤差逆伝播が可能となる。
未知変数の生成
未知変数を生成する確率分布は次式で与えられた。 \begin{equation} p(\vec{x}_*|X)=\int d\vec{z}\;p(\vec{x}_*|\vec{z})p(\vec{z}|X) \end{equation} 事後確率$p(\vec{z}|X)$の近似解$q_{\phi}(\vec{z}|X)$を用いると \begin{equation} p(\vec{x}_*|X)\approx\int d\vec{z}q_{\phi}(\vec{z}|X)p(\vec{x}_*|\vec{z}) \end{equation} を得る。先と同様に再パラメータ化トリックを適用すると \begin{equation} p(\vec{x}_*|X)\approx\int d\vec{\epsilon}\mathcal{N}(\vec{\epsilon}|\vec{0},I_D)p(\vec{x}_*| \vec{z}=\vec{\mu}_{\phi}(X)+\Sigma_{\phi}^{1/2}(X)\vec{\epsilon}) \end{equation} となる。
Chainer実装の確認
ChainerのサンプルコードにVAEがある。これはMNISTデータセットにVAEを適用したものである。MNISTは2値画像であるから$\vec{x}_n$として0と1が784(=28$\times$28)個並んだベクトルを考えることになる。実際にコードを見て行く前に先に導出した式をもう少し詳細に計算しておく。
最初に$\vec{\mu}_{\phi}(X)$と$\Sigma_{\phi}(X)$を次のように置く。 \begin{eqnarray} \vec{\mu}_{\phi}(X)&=&(\mu_{\phi,1}(X),\cdots,\mu_{\phi,D}(X))^T \label{eq5}\\ \Sigma_{\phi}(X)&=&\mathrm{diag}(\sigma^2_{\phi,1}(X),\cdots,\sigma^2_{\phi,D}(X)) \label{eq6} \end{eqnarray} このとき式(\ref{eq4})は次式となる。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]= \frac{1}{2} \sum_{d=1}^{D}\left\{ -\ln{\sigma^2_{\phi,d}(X)}-1+\sigma^2_{\phi,d}(X)+\mu_{\phi,d}^2(X) \right\} \label{eq8} \end{equation} また、$\vec{z}$の成分は次式で与えられる。 \begin{equation} z_d=\mu_{\phi,d}(X)+\sigma_{\phi,d}(X)\epsilon_d \end{equation} 観測値が独立同分布に従うと仮定すると対数尤度は以下のように変形される。 \begin{equation} \ln{p(X|\vec{z})}= \sum^{N}_{n=1}\ln{p(\vec{x}_n|\vec{z})} \end{equation} $\vec{x}_n$の次元数を$M$(=784)とすると \begin{equation} \ln{p(\vec{x}_n|\vec{z})}=\sum_{m=1}^{M}\ln{p(x_{n,m}|\vec{z})} \end{equation} となる。いま考える画像は0と1から構成される。従って、$p(x_{n,m}|\vec{z})$として0と1を生成する確率分布であるBernoulli分布を仮定する。 \begin{eqnarray} p(x_{n,m}|\vec{z})&=&\mathrm{Bern}\left(x_{n,m}|\eta_{\theta,m}\left(\vec{z}\right)\right) \\ \mathrm{Bern}(x|\eta)&=&\eta^{x}(1-\eta)^{1-x} \end{eqnarray} $\eta_{\theta,m}\left(\vec{z}\right)$は、入力$\vec{z}$、パラメータ$\theta$のネットワークで学習される量である。 以上を踏まえて処理の流れを書き直すと下図となる。

以上で準備が整ったので順にコードを見ていく。まず最初にネットワークを定義したクラスVAEを見る。コンストラクタは以下の通り。 Encoderとして$\vec{\mu}_{\phi}(X)$と$\Sigma_{\phi}(X)$を生成する層がそれぞれ1層ずつ定義されている。Decoderとして$\vec{\eta}_{\theta}(\vec{z})$を生成する2層が定義されている。次に関数encodeを見る。 $\mu_{\phi,d}$と$\ln{\sigma_{\phi,d}^2}$を生成する処理が記述されている。次は関数decodeである。 $\vec{z}$を受け取り$\vec{\eta}_{\theta}(\vec{z})$を返す処理が記述されている。次は__call__である。 Encoderで計算した平均を入力としてDecoderを呼び出している。分散を無視して復号化している。次はget_loss_funcである。
まとめ
今回は、VAEをBayes推論の枠組みで解説し、Chainerのサンプルコードを見た。ニューラルネットワークで計算されるのは確率分布のパラメータであることを明確に示した。言い換えると他の手法でパラメータを計算できるのであればそれでも構わないということである。計算の仮定で確率分布にいくつかの仮定(ガウス分布やBernoulli分布)をしていることに注意しなければならない。今回Bernoulli分布を使用したのはターゲットとした観測値が0と1から構成される2値画像であるためである。2値でない観測値を対象とするならそれに見合った確率分布を導入する必要がある。次回はChainerのコードを動かして得られる結果を考察したい。
いま考える画像は0と1から構成されるのでベルヌーイ分布を仮定する、とのことですが、画像が0と1から構成されていない場合はどういった分布を仮定するのですか
返信削除画像が任意の実数値から構成されているなら、任意の実数値を生成できる確率分布(扱いやすさから正規分布かな)を使えば良いと思います。
削除