2015年4月29日水曜日
2015年4月2日木曜日
Convolutional Neural Network によるシーン認識
はじめに
先のページで Convolutional Neural Network(CNN)を解説した。今回は、CNN をシーン認識に適用した結果を示す。
データセット
このページに置いてある データ(LSP15)を使用した。このデータは15個のディレクトリから構成される。
- bedroom
- CALsuburb
- industrial
- kitchen
- livingroom
- MITcoast
- MITforest
- MIThighway
- MITinsidecity
- MITmountain
- MITopencountry
- MITstreet
- MITtallbuilding
- PARoffice
- store
データセットの増量
各シーンの画像の枚数は以下の通りである。
| シーン名 | 枚数 |
|---|---|
| MITcoast | 360(720) |
| MIThighway | 260(520) |
| MITmountain | 374(748) |
| MITstreet | 292(584) |
| MITforest | 328(656) |
| MITinsidecity | 308(616) |
| MITopencountry | 410(820) |
| MITtallbuilding | 356(712) |
| 総数 | 2688(5376) |
画像の枚数を増やすため、各画像の左右反転画像を追加した。括弧内が追加後の枚数である。
データセットの分割
データセットを train、validation、test の3つに分割する。枚数の比を train : validation : test = 5 : 1 : 1 とした。 以下に具体的な枚数を示す。
| ラベル名 | シーン名 | train | validation | test |
|---|---|---|---|---|
| 0 | MITcoast | 514 | 102 | 102 |
| 1 | MIThighway | 371 | 74 | 74 |
| 2 | MITmountain | 534 | 106 | 106 |
| 3 | MITstreet | 417 | 83 | 83 |
| 4 | MITforest | 468 | 93 | 93 |
| 5 | MITinsidecity | 440 | 88 | 88 |
| 6 | MITopencountry | 585 | 117 | 117 |
| 7 | MITtallbuilding | 508 | 101 | 101 |
| 総数 | 3837 | 764 | 764 |
また、シーン認識時に使用するラベルを上図の第1列のように定義した。 左右反転画像は元の画像とは独立した画像として扱い、train / validation / test の3つに分ける際は乱数を用いた。
ネットワークの構造
今回使用したネットワークの構造は以下の通りである。
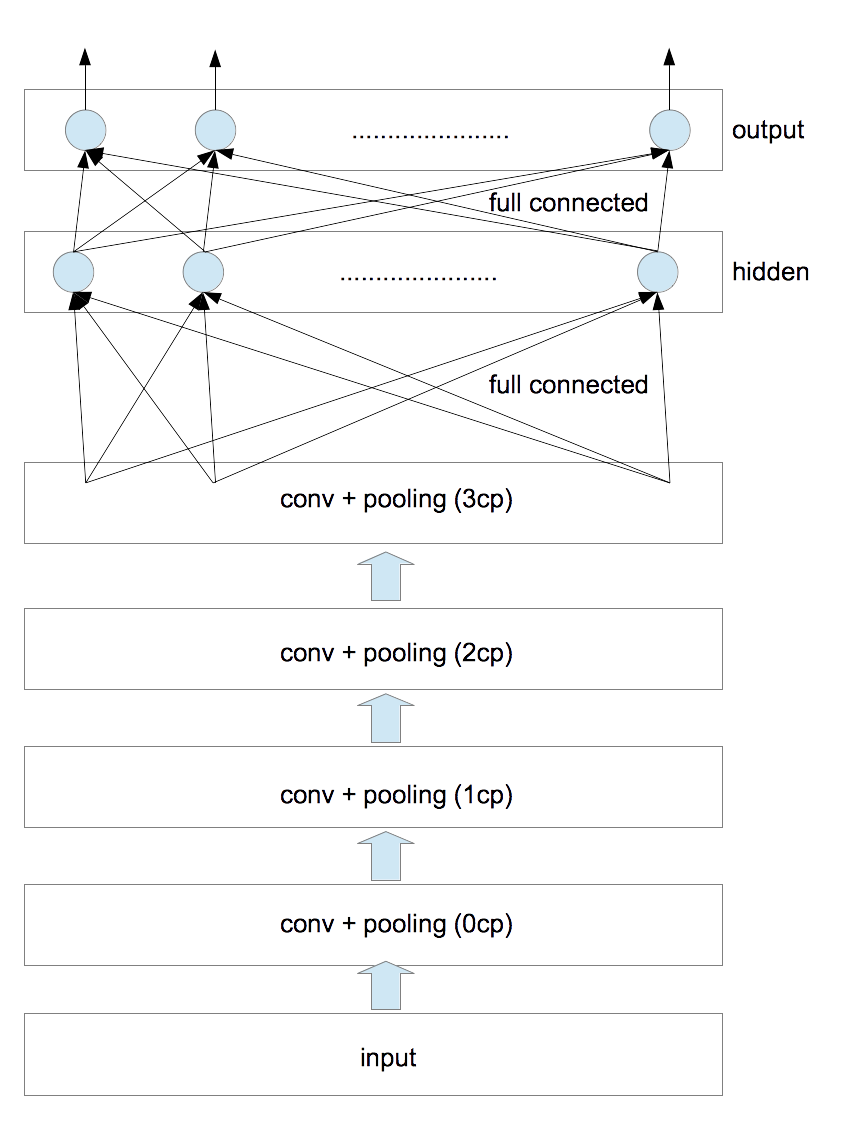
| 層名 | フィルタサイズ | フィルタの個数 | pooling |
|---|---|---|---|
| 0cp | 5$\times$5 | 2 | 2$\times$2 |
| 1cp | 6$\times$6 | 10 | 2$\times$2 |
| 2cp | 6$\times$6 | 50 | 2$\times$2 |
| 3cp | 5$\times$5 | 200 | 2$\times$2 |
フィルタサイズとは、convolution 時に使用する矩形画像のサイズのことである(フィルタの各要素の値は訓練時に決定される)。また、convolution時の stride は全て1とした。poolingはmax poolingを採用した。poolingのあと画像サイズは縦横ともに1/2になる。 隠れ層と出力層のユニット数は以下の通りである。
| 層名 | ユニット数 |
|---|---|
| 隠れ層 | 500 |
| 出力層 | 8 |
各層における画素数の変遷は次のようになる。
| 層名 | 入力サイズ | conv後のサイズ | pooling後のサイズ |
|---|---|---|---|
| 0cp | 146$\times$146 | 142$\times$142 | 71$\times$71 |
| 1cp | 71$\times$71 | 66$\times$66 | 33$\times$33 |
| 2cp | 33$\times$33 | 28$\times$28 | 14$\times$14 |
| 3cp | 14$\times$14 | 10$\times$10 | 5$\times$5 |
0cp層への入力画像に対しては、画素値を255で割ったあと、平均値が0、分散が1となるように正規化した。 3cp層から出力される画素の数は5000=(5$\times$5$\times$200)である。これが隠れ層への入力値となる。今考えているラベルの総数は8であるから出力層のユニット数は8となる。
計算方法
Convolutional Neural Networks (LeNet) にあるサンプルソース(theanoによる実装)に手を加え計算を行なった。主な変更点は以下の通りである。
- 上に示したネットワーク構造に変更した。
- $L_1$正則化項と$L_2$正則化項を追加した。
- 各epochごとに学習率が減衰していくようにした。
- 隠れ層の活性化関数をsigmoidとした(tanhより精度が良くなった)。
| 学習率 | 減衰率 | $L_1$正則化項の重み | $L_2$正則化項の重み |
|---|---|---|---|
| 0.01 | 0.995 | 0.0002 | 0.0002 |
元のソースでは、early-stoppingと呼ばれる手法を使って訓練を行っている。「訓練データ(train)で学習したあと検証データ(validation)で誤り率を見る」を、検証データで改善が見られなくなるまで繰り返す手法である。この部分はそのまま踏襲した。
計算環境
アマゾンのEC2インスタンス(g2.2xlarge)を利用した。これは1536CUDA コアと 4GB のビデオメモリを搭載しており、今回の計算ではtheanoを通してGPUを利用した。
結果
0/1損失(0/1 loss)の結果を以下に示す。
| best validation score | test performance |
|---|---|
| 11.9736842105% | 10.6578947368% |
ここで、best validation score とは、early-stopping の反復計算の過程で得られた「検証データ」に対する最適値である。 「検証データ」に対する最適値を実現したときのモデルを使って「テストデータ」を評価した結果が test performance である。 ただし、反復時の epoch 数の上限値を500とした。計算時間は 182.905974067 分であった。
考察
- 左右反転画像を追加する前の誤り率は20%程度であり、これ以上減らすことができなかった。
- 左右反転画像を追加した後の誤り率は10%程度となり改善された。
- 白色化や隠れ層の追加などを試みたがこれ以上は改善しなかった。
- なんとかして誤り率を一桁にしたいのだが。。。
登録:
コメント (Atom)