はじめに
先のページで、Variational Auto Encoder(VAE)を実装したChainerのサンプルコードをそのまま動かし、生成される画像を見た。符号化・復号化して得られる画像は、入力画像をそれなりに再現していたが、乱数から生成される画像は精度が良くないことを示した。今回は、サンプルコードに手を加えて実験を行う。
ソースコードの場所
今回のソースコードはここにある。
評価基準
このページで示したように、勾配降下法で最適化すべき式は次式である。 \begin{equation} \min_{\phi} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}|X) \right] = \min_{\phi} {\left[ D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]-E_{q_{\phi}(\vec{z}|X)}\left[\ln{p(X|\vec{z})}\right] \right] } \end{equation} この右辺第1項は次のように書けた。 \begin{equation} D_{KL} \left[ q_{\phi}(\vec{z}|X)||p(\vec{z}) \right]= \frac{1}{2} \sum_{d=1}^{D}\left\{ -\ln{\sigma^2_{\phi,d}(X)}-1+\sigma^2_{\phi,d}(X)+\mu_{\phi,d}^2(X) \right\} \label{eq1} \end{equation} また、潜在変数$\vec{z}$の成分は次式で与えられた。 \begin{equation} z_d=\mu_{\phi,d}(X)+\sigma_{\phi,d}(X)\epsilon_d \end{equation} 式(\ref{eq1})で理想的な最適化を実現できれば、$\mu_{\phi,d}(X)\rightarrow 0,\sigma_{\phi,d}(X)\rightarrow 1$とできる。このとき、$\vec{z}$は標準正規分布から生成される値$\vec{\epsilon}$に置き換えることができる。net.py内にある関数decodeは本来ならば$\vec{z}$を与えて画像を生成するコードであるが、実際に使われる際は標準正規分布から作られる値を与えている。従って、上記の収束が不十分であると、意図した振る舞いをしないことになる。最適化を行う際に、$\mu_{\phi,d}(X)$と$\sigma_{\phi,d}(X)$の値の変化も追跡すべきである。以上の考察に基づきnet.pyに実装されている関数get_loss_funcを以下のように変更した。
def get_loss_func(self, C=1.0, k=1):
"""Get loss function of VAE.
The loss value is equal to ELBO (Evidence Lower Bound)
multiplied by -1.
Args:
C (int): Usually this is 1.0. Can be changed to control the
second term of ELBO bound, which works as regularization.
k (int): Number of Monte Carlo samples used in encoded vector.
"""
def lf(x):
mu, ln_var = self.encode(x)
mean_mu, mean_sigma = calculate_means(mu, ln_var)
batchsize = len(mu.data)
# reconstruction loss
rec_loss = 0
for l in six.moves.range(k):
z = F.gaussian(mu, ln_var)
rec_loss += F.bernoulli_nll(x, self.decode(z, sigmoid=False)) \
/ (k * batchsize)
self.rec_loss = rec_loss
kl = gaussian_kl_divergence(mu, ln_var) / batchsize
self.loss = self.rec_loss + C * kl
chainer.report(
{
'rec_loss': rec_loss,
'loss': self.loss,
'kl': kl,
'mu': mean_mu,
'sigma': mean_sigma,
},
observer=self)
return self.loss
return lf
12行目でmuとsigmaの平均値を計算している。これに伴い、実行中にコマンドラインに表示する項目を増やしている( 25行目から29行目)。関数calculate_meansの中身は以下の通りである。
def calculate_means(mu, ln_var):
xp = chainer.cuda.get_array_module(mu)
mean_mu = xp.mean(mu.data)
sigma = xp.exp(ln_var.data / 2)
mean_sigma = xp.mean(sigma)
return mean_mu, mean_sigma
実験-1
先のページと同じパラメータ(epoch=100,dimz=20)で実行したときのmuとsigmaの変化は以下の通りである。
mu

sigma
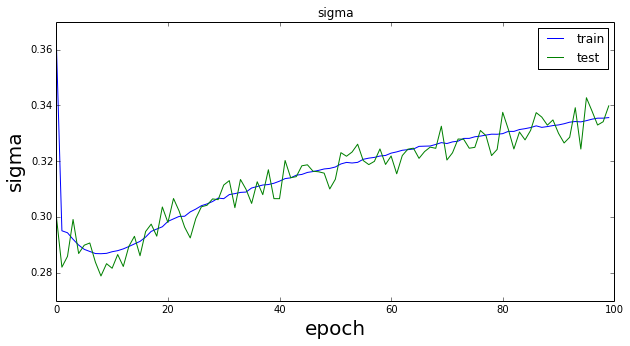
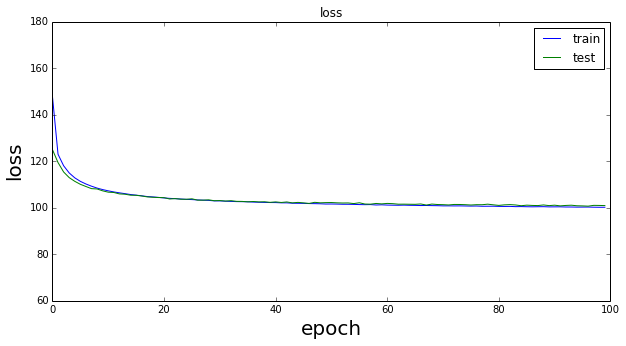
訓練データに対するmuの値は0近傍を推移しているがepochの後半部分で振動しており、テストデータに対するそれは終始振動していることが分かる。sigmaの方は1からは程遠い値である。このときのトータルのlossは以下のようになる。
loss
実験-2
次に、こちらで紹介されている実装で実験を行った。ソースコード内にnet_2.pyとして保存してある。epoch=100、dimz=100とした結果を以下に示す。
mu

sigma

muもsigmaもかなり改善されていることが分かる。muは0に、sigmaは1に近づいている。このときのトータルのlossは以下のようになる。
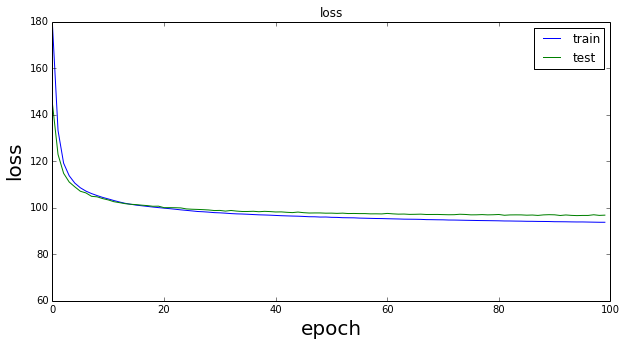
こちらも少しだけ改善されている。
生成画像の比較
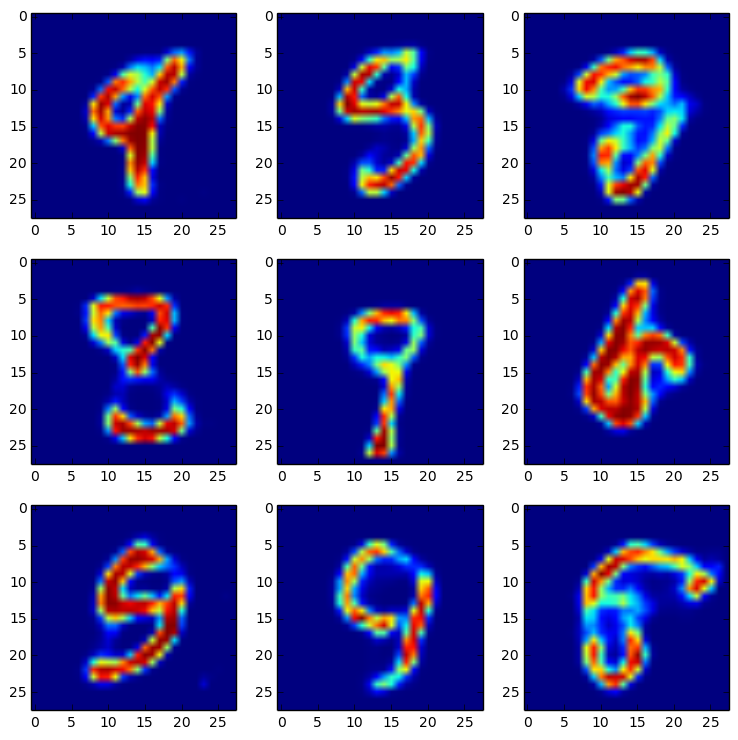
実験-1と2で、標準正規分布から生成した同じ乱数値から復号された画像を示す。
実験-1
実験-2

後者の方が数字であることを判別できるので精度は良くなっている(と思う)。
まとめ
今回は、Chainerのサンプルコードに手を加えて実験を行った。muは0に、sigmaは1に近い方が復号化される画像の精度も上がることを示した。VAEを使用する場合、lossだけでなく、muやsigmaの値の推移も確認した方が良い。
0 件のコメント:
コメントを投稿