はじめに
「Your Classifier Is Secretly An Energy Based Model And You Should Treat It Like One」をまとめる。
概要
Energy Based Model
パラメータ$\theta$を持つ同時確率分布$p_{\theta}({\bf x},y)$をボルツマン分布を用いて表す。 \begin{equation} p_{\theta}({\bf x},y)=\frac{\exp{ \left( -E_{\theta} ({\bf x},y) \right) } }{Z(\theta)} \label{eq1} \end{equation} $E_{\theta}({\bf x},y)$はエネルギーであり、その定義については後述する。$Z(\theta)$は次式で定義される分配関数である。 \begin{equation} Z(\theta)=\int dx\int dy \exp{ \left( -E_{\theta} ({\bf x},y) \right) } \label{eq2} \end{equation} 式(\ref{eq1})のように確率分布をボルツマン分布を用いて表すモデルを、Energy Based Modelと呼ぶ。式(\ref{eq1})を$y$について周辺化して \begin{equation} p_{\theta}({\bf x}) = \int dy\;p_{\theta}({\bf x},y) \label{eq3} \end{equation} を得る。いま、$p_{\theta}({\bf x})$に対してもボルツマン分布を仮定する。 \begin{equation} p_{\theta}({\bf x})=\frac{\exp{\left(-E_{\theta}({\bf x})\right)}}{Z(\theta)} \label{eq5} \end{equation} これを変形すると \begin{eqnarray} \exp{\left(-E_{\theta}({\bf x})\right)} &=& Z(\theta)p_{\theta}({\bf x})\nonumber\\ &=& Z(\theta) \int dy\;p_{\theta}({\bf x},y)\nonumber\\ &=& Z(\theta) \int dy \frac{\exp{ \left( -E_{\theta} ({\bf x},y) \right) }}{Z(\theta)}\nonumber\\ &=& \int dy \exp{ \left( -E_{\theta} ({\bf x},y) \right) } \label{eq6} \end{eqnarray} 両辺の対数を取り \begin{equation} E_{\theta}({\bf x})=-\ln{\left( \int dy \exp{ \left( -E_{\theta} ({\bf x},y) \right) } \right) } \label{eq7} \end{equation} を得る。ここまでの手順をまとめると以下のようになる。
- エネルギー$E_{\theta}({\bf x},y)$を与える。
- 式(\ref{eq1})から$p_{\theta}({\bf x},y)$を計算する。
- 式(\ref{eq7})から$E_{\theta}({\bf x})$を計算する。
- 式(\ref{eq5})から$p_{\theta}({\bf x})$を計算する。
エネルギーの定義
$E_{\theta}({\bf x},y)$について考えるため、従来の識別器の構成を示す(下の左図)。

最適化
学習時に最大化する目的関数は次式である。 \begin{equation} \ln{p_{\theta}({\bf x},y)}=\ln{p_{\theta}({\bf x})}+\ln{p_{\theta}(y|{\bf x})} \label{eq9} \end{equation} 第2項の最大化は従来とおりクロスエントロピーを用いれば良い。第1項の最大化については以下のようにする。最初に、式(\ref{eq5})の両辺の対数をとる。 \begin{equation} \ln{p_{\theta}({\bf x})}=-E_{\theta}({\bf x})-\ln{Z(\theta)} \end{equation} $\theta$で微分すると \begin{equation} \frac{\partial\ln{p_{\theta}({\bf x})}}{\partial\theta}=-\frac{\partial E_{\theta}({\bf x})}{\partial\theta} -\frac{1}{Z(\theta)}\frac{\partial Z(\theta)}{\partial\theta} \end{equation} ここで \begin{equation} Z(\theta)=\int dx \exp{\left(-E_{\theta}({\bf x})\right)} \end{equation} であるから、これを$\theta$で微分すると \begin{equation} \frac{\partial Z(\theta)}{\partial\theta}=\int dx \exp{\left(-E_{\theta}({\bf x})\right)}\left(-\frac{\partial E_{\theta}({\bf x})}{\partial\theta}\right) \end{equation} 故に \begin{eqnarray} \frac{1}{Z(\theta)}\frac{\partial Z(\theta)}{\partial\theta} &=& -\int dx \frac{\exp{\left(-E_{\theta}({\bf x})\right)}}{Z(\theta)} \left(\frac{\partial E_{\theta}({\bf x})}{\partial\theta}\right)\nonumber\\ &=& -\int dx p_{\theta}({\bf x}) \left(\frac{\partial E_{\theta}({\bf x})}{\partial\theta}\right)\nonumber\\ &=&-\mathbb{E}_{ p_{\theta}({\bf x}) } \left[ \frac{\partial E_{\theta}({\bf x})}{\partial\theta} \right] \end{eqnarray} となる。最後の等式は$p_{\theta}({\bf x})$による期待値であることを表す。以上から \begin{equation} \frac{\partial\ln{p_{\theta}({\bf x})}}{\partial\theta}=-\frac{\partial E_{\theta}({\bf x})}{\partial\theta} +\mathbb{E}_{ p_{\theta}({\bf x}) } \left[ \frac{\partial E_{\theta}({\bf x})}{\partial\theta} \right] \end{equation} を得る。$E_{\theta}({\bf x})$は式(\ref{eq7})により計算することができる。上式の第2項は分布$p_{\theta}({\bf x})$からサンプリングする必要がある。 本文献で使用するサンプリング手法は以下の通りである。 \begin{eqnarray} {\bf x}_{0}&\sim&p_0({\bf x}) \nonumber\\ {\bf x}_{i+1}&=&{\bf x}_i-\frac{\alpha}{2}\frac{\partial E_{\theta}({\bf x}_i)}{\partial {\bf x}_i}+\epsilon\nonumber\\ \epsilon&\sim&\mathcal{N}(0,\alpha) \end{eqnarray} ここで、$p_0({\bf x})$は一様分布である。本手法は、Stochastic Gradient Langevin Dynamics(SGLD)をベースにしたものである(詳細は略)。式(\ref{eq9})の第1項は教師なし学習、第2項は教師あり学習を行う。
実験
Hybrid Modelint
従来手法と比較したのが下図である。使用したデータセットは、CIFAR10である。

Calibration
較正済み識別器(calibrated classifier)とは、$\max_y{p(y|{\bf x})}$(確信度)が正解率(accuracy)と比例するような識別器のことである。高い確信度を持って予測されたラベルは高い確率で正解となり、低い確信度で予測されたラベルは、誤認識である確率が高くなる。較正されているか否かを可視化する手順は以下の通り。
- データセット内の各サンプル${\bf x}_i$ごとに$\max_y{p(y|{\bf x}_i)}$を算出し、これらを等区間のバケットに振り分ける(ヒストグラムを作る)。例えば0から1までの区間を20等分した場合、20個のバケットに振り分ける。
- 各バケットに属するサンプルから平均精度を算出し、このバケットの高さとする。
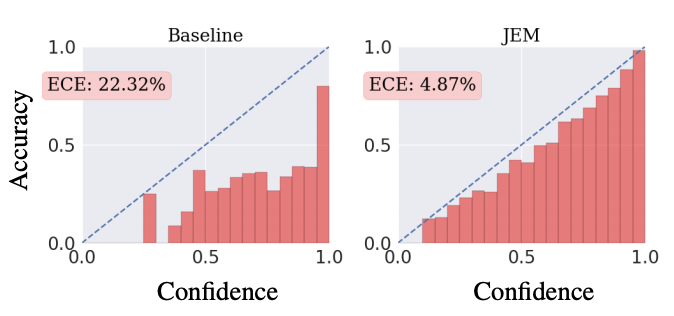
較正度合いを定量化する指標が、次式で定義されるExpected Calibration Error(ECE)である。 \begin{equation} {\rm ECE}=\sum_{m=1}^{M}\frac{|B_m|}{n}|{\rm acc}(B_m)-{\rm conf}(B_m)| \end{equation} ここで、$M$はバケットの数、$n$はデータセット内のサンプル総数、$B_m$は1つののバケット中に格納されるサンプルの集合、$|B_m|$はサンプル数、${\rm acc}(B_m)$は集合$B_m$を用いて計算された平均精度、${\rm conf}(B_m)$は集合$B_m$を用いて計算された平均確信度である。${\rm ECE}$が小さくなるほど較正度合いは良くなり、完全に較正されている場合は0になる。上図に見るように、従来手法による識別器より、JEMで訓練した識別器の方が${\rm ECE}$は小さい。
Out-Of-Distribution Detection
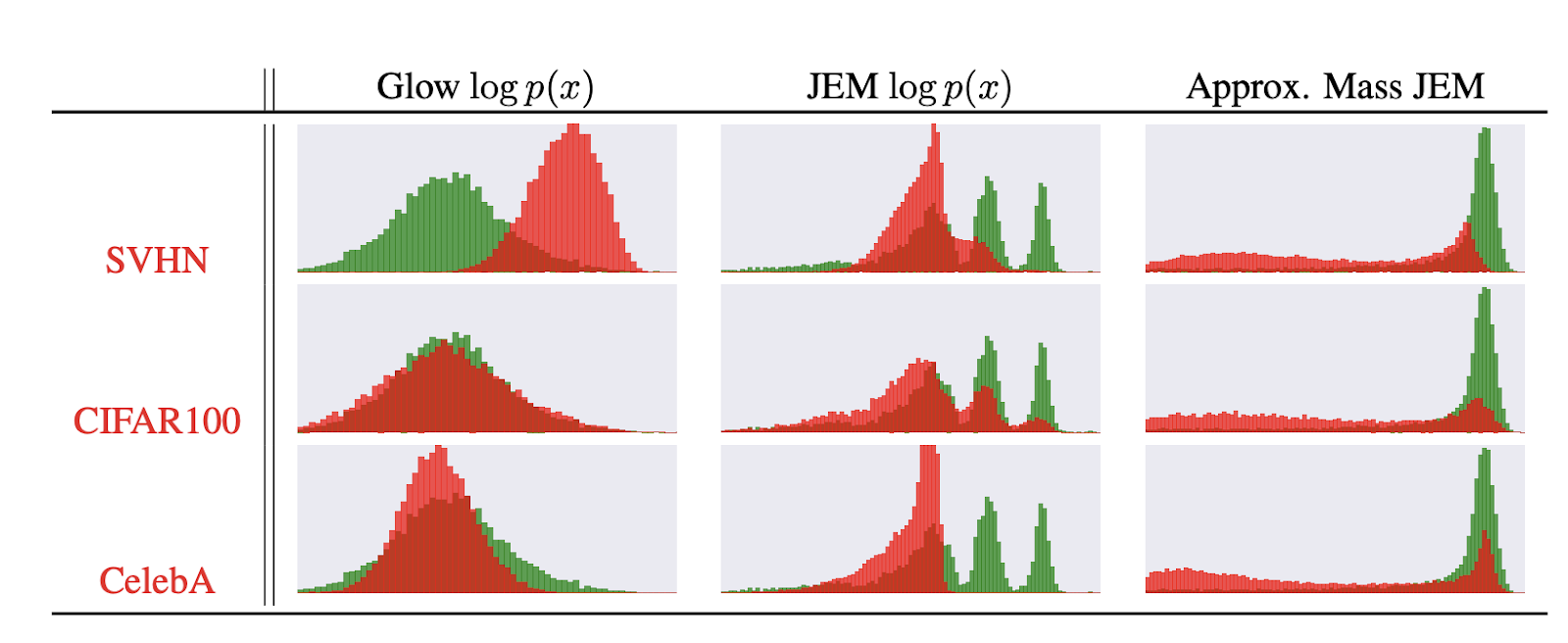
分布外検知とは例えば以下のような識別器を作ることである(引用元)。

データセットCIFAR10で訓練した識別器に別の3つのデータセットSVHN、CIFAR100、CelebAを与えときのサンプルの対数分布($\ln{p(x)}$)を示したのが下図である。
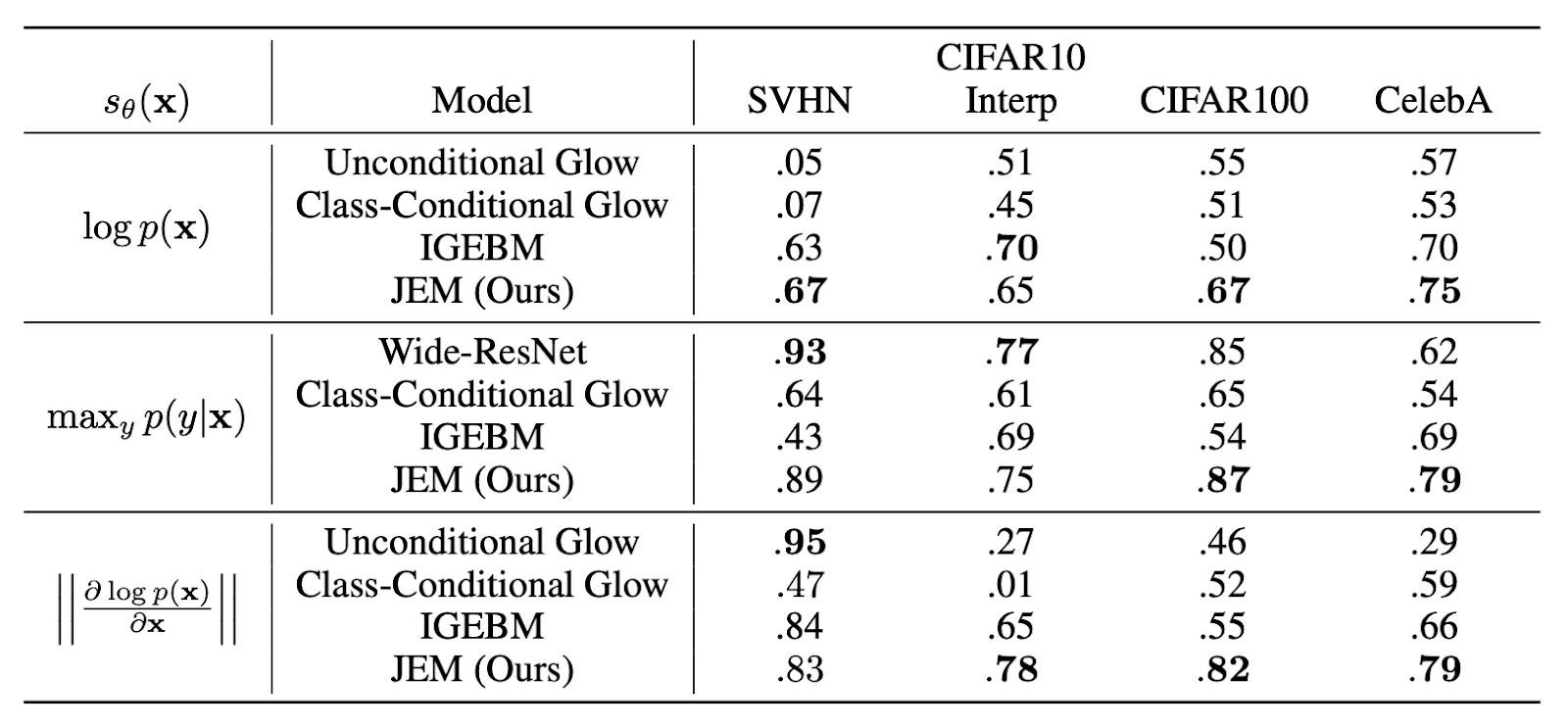
分布外検知に成功している多くの手法が採用している指標が次式である。 \begin{equation} s_{\theta}({\bf x})=\max_y{p_{\theta}(y|{\bf x})} \end{equation}
Robustness
JEMは敵対的サンプルに対しても頑健であると主張されている(詳細は略)。
0 件のコメント:
コメントを投稿